When I began training video-based AI models at FixThePhoto, I learned that the right video dataset for machine learning matters more than the model itself. A suitable dataset helps the AI understand how objects move, behave, and the temporal sense.
A bad dataset only confuses the model and leads to unstable results. I dealt with many problems, including wrong labels, poor video quality, and uneven annotations, so I decided to test datasets on my own instead of trusting descriptions.
I gathered, compared, and tested 9 video datasets for machine learning. I checked how many different actions they contained, how accurate the labels were, how clear the videos looked, and how smoothly models trained on them.

Many people believe that building a strong video AI model starts with choosing the best algorithm, but the real starting point is choosing a dataset that actually teaches the model something useful.
When I prepare video datasets for machine learning, I look at each clip as if it were a short story. There should be a clear start, a main action, and an ending. The plan is to give the model clear and logical sequences, not just throw random videos into training. Movement should be easy to see, subjects should be clear, and the camera view should stay consistent.
If the dataset feels messy, the model will learn messy patterns.
This method matches what many US research labs now suggest. Several university studies talk about temporal signal density. This means that every second of video should contain information related to the task the AI is learning. If part of a video teaches nothing, it only slows training and adds confusion. I follow the same idea by shortening timelines and keeping only useful content.
Long breaks, random camera movement, scene changes, and background activity all act as noise. The model may focus on these instead of the real action. When those parts are removed, only the important movement remains – the information the AI needs to learn patterns correctly.
When you treat a video dataset for ML like a storyboard instead of a random collection of clips, since the model stops guessing and starts understanding what it sees, training becomes faster, learning becomes clearer, and results become more accurate.

Best for: building broad, high-diversity action models
Kinetics-700 was one of the first video datasets I tried when I started building an action recognition model, and it’s no wonder many people call it the “ImageNet of video”: it includes a huge variety of human actions (from simple hand movements to complex interactions between people).
Because of this range, models trained on it must learn real motion over time instead of relying on single frames. During my first training runs, the model became stable faster and performed better on new data than it did with smaller datasets.
One reason Kinetics-700 is so useful is that the videos are unpredictable – lighting changes, camera angles differ, backgrounds vary, and video quality is not always the same. This kind of variation is common in real-world data, so the dataset helps models learn how to handle messy input instead of failing when conditions change slightly.
Nevertheless, the dataset is not perfect. Some clips need to be trimmed, cleaned, or re-encoded before training. I usually remove or fix low-quality clips to prevent the model from learning bad patterns. This step is especially important when I prepare motion data for tools like AI 3D model generators, which need clean and consistent motion over time.
Even with these flaws, Kinetics-700 is still the video dataset for ML I rely on when I need a strong and flexible base for a video model. It teaches patterns that transfer well to other tasks, such as recognizing gestures or understanding complex actions in different settings.
“When I train with Kinetics-700, I always clean up poor-quality clips first. This helps the model train faster and keeps the learning process more stable.”

Best for: fast prototyping and baseline checks
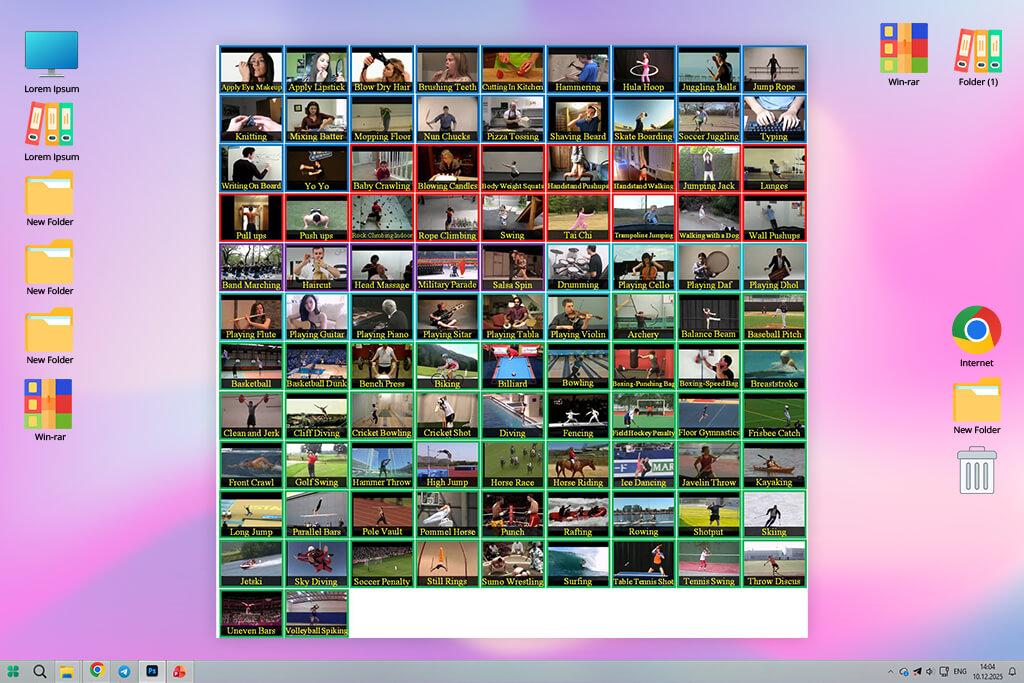
UCF101 is the first machine learning video dataset I use when testing a new training setup or model. It is small, easy to work with, and very consistent. This makes it ideal for checking whether a model can learn basic actions without spending a long time. Even though it is an older dataset, it still works well as a basic test before moving on to larger datasets like Kinetics or ActivityNet.
What I like about UCF101 is how clearly the videos are sorted into action categories. You can set up data loading quickly and start training almost right away.
However, this simplicity is also a downside: the scenes are controlled, the video quality is low, and the data does not reflect how complex real-world videos are. It is not suitable for final production models, but it is very useful for building, testing, or fixing a training setup.
Whenever I need a fast and lightweight video dataset to try out a new idea, UCF101 remains one of the safest choices.
Best for: frame-level human action analysis
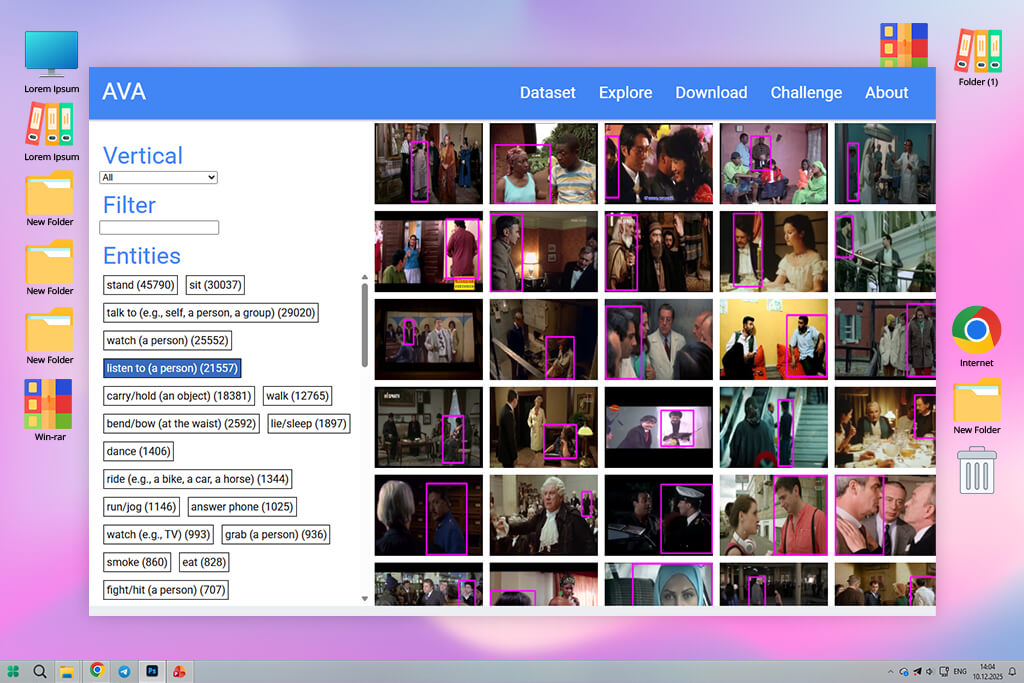
Working with this machine learning video dataset felt like using data made for models that need to understand human behavior in detail. Instead of labeling entire video clips, AVA marks actions frame by frame. This makes it extremely useful for training spatio-temporal models.
The dataset forces models to pay attention to small movements, such as standing, talking, waving, or picking up objects, all linked to exact moments in the video.
Because AVA is more complex, it needs careful preparation. The annotation format can feel confusing at first, but once the labels are correctly matched with video segments, the dataset becomes very powerful.
I have seen the best results with AVA in projects related to surveillance, gesture recognition, and situations where multiple people are acting at the same time. It is especially helpful in projects that integrate AI and photography, where understanding precise human actions is important.
“I always look at a few labeled frames before training. This helps avoid many mistakes caused by misaligned timestamps.”

Best for: large-volume sports motion pretraining
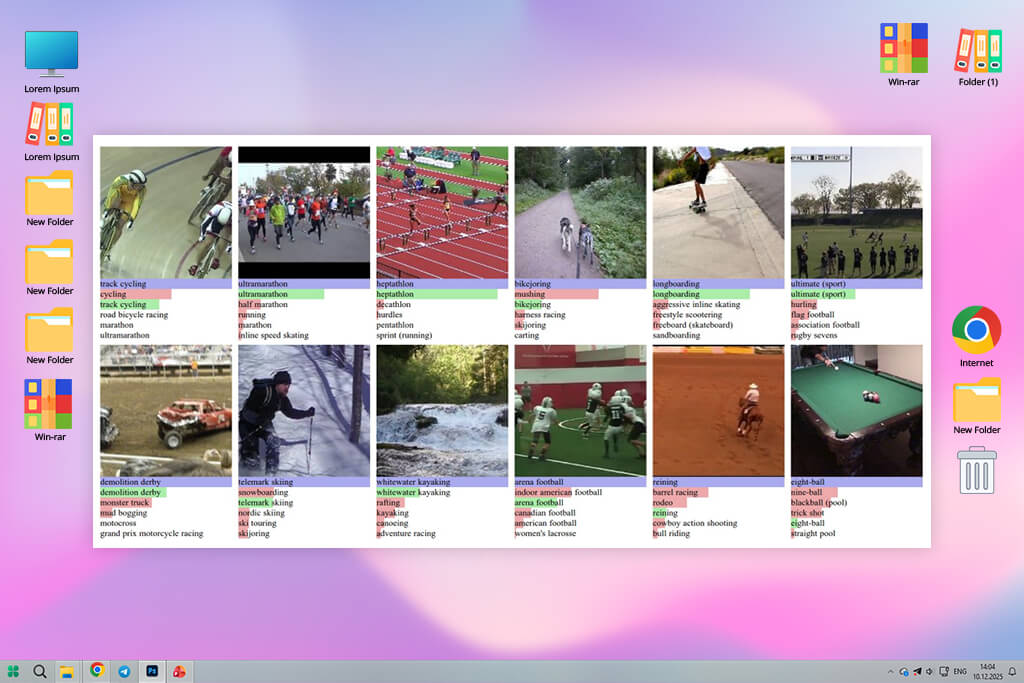
When I need a huge amount of motion data for pretraining a model, I use Sports-1M. Its large size allows models to learn movement patterns that smaller datasets cannot provide. Sports videos often include fast motion, blocked views, and camera movement, which helps prepare models for harder tasks later.
The main difficulty with Sports-1M is its scale. Downloading the data, organizing it, and preparing it for training takes time and strong hardware. It is not as clean or structured as datasets like UCF101, but the large number of examples helps produce strong results, especially for action recognition. For large transformer-based video models, it is a solid starting point.
What I find most useful is how well models trained on Sports-1M adapt afterward. Even when adjusted on non-sports data, the model already understands motion. It handles blur, quick changes, and partially hidden objects with more confidence. For teams with enough computing capacity, Sports-1M remains one of the best video datasets for large-scale pretraining.
Best for: quick semantic video classification
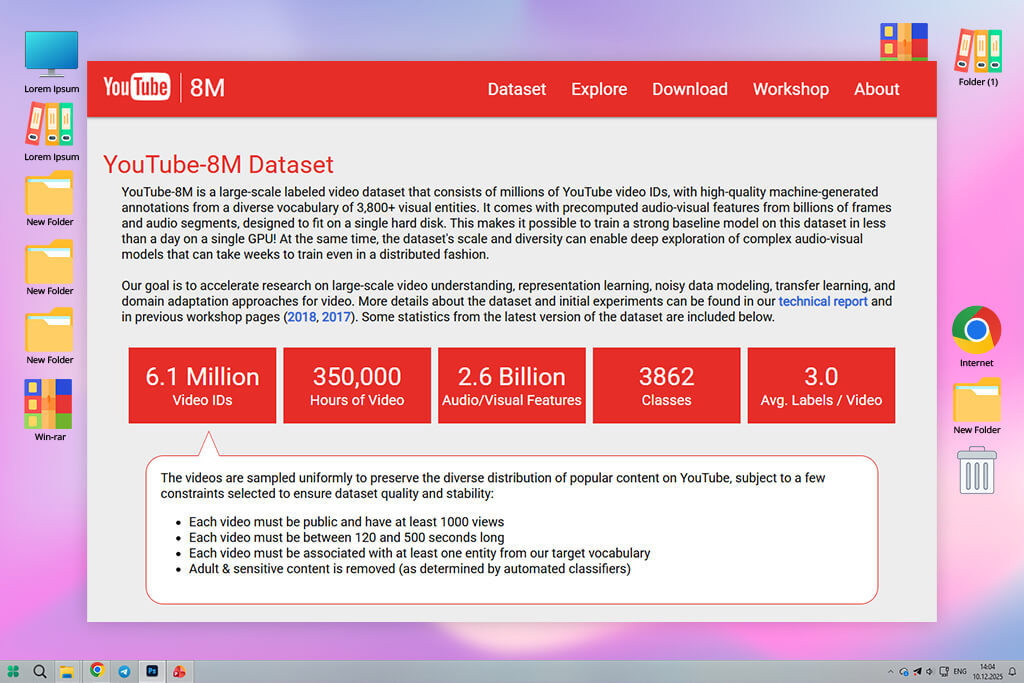
YouTube-8M is the dataset I choose when I need a large amount of data without dealing with huge video files. Instead of full videos, it comes with pre-made visual and audio features, making the testing process much faster. The downside is that you cannot work with individual frames or study motion directly, since the raw videos are not included.
Even with that limitation, the dataset is very useful because of its size and variety. Models trained on YouTube-8M quickly learn high-level topics such as sports, music, food, or daily activities, even though the visual information is simplified.
I also like using YouTube-8M when comparing different model designs or testing artificial intelligence software. Since the data format is lightweight, you can train and test models quickly. If your project does not depend on fine motion details and you want fast experiment cycles, YouTube-8M is one of the most practical choices.
“I always check that the labels match my final goal. This avoids wasting time later when adjusting the model.”

Best for: object tracking and segmentation tasks
COCO-VID is not a massive machine learning video dataset, but it stands out because of how accurate it is. The video clips are short, so you do not get long sequences of motion. However, for tracking-focused models, the dataset provides clean segmentation masks and stable bounding boxes.
I have used COCO-VID many times for tracking experiments, and the high-quality annotations always make training more stable. If your main goal is to track objects instead of understanding long actions or behavior, COCO-VID offers exactly what is needed.
Best for: autonomous driving model training
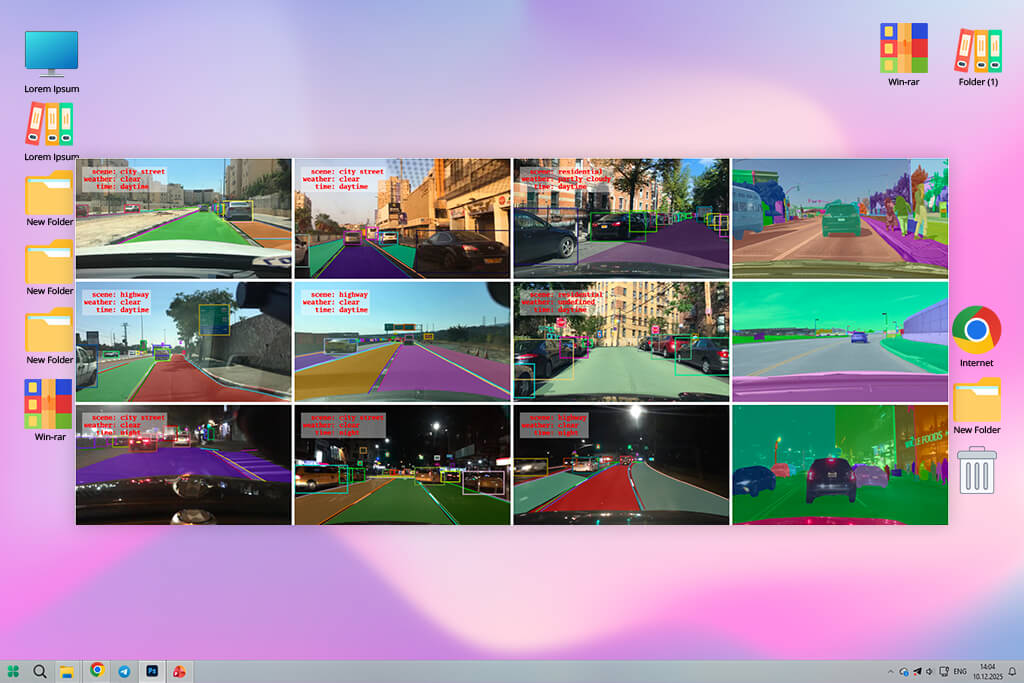
BDD100K is one of the most realistic video datasets for driving tasks, and this realism explains both its strength and its weakness. The videos are recorded in many different conditions, including bad weather, changing light, and dirty camera lenses. Because of this, the annotation quality is not always perfectly consistent, and you can notice this during training.
However, this variation forces models to learn how to handle real-world situations instead of flawless settings. Tasks like lane detection, object tracking, and segmentation benefit from this challenge.
When testing self-driving systems or comparing results with some of the best AI video generators, this realism helps models perform better outside controlled tests. If you are working on autonomous driving, very few datasets prepare models for real roads as well as BDD100K.
“When I use BDD100K, I process night videos separately. Balancing lighting domains early helps the model learn faster.”

Best for: fine-grained motion understanding

Something-Something V2 is a dataset that focuses almost entirely on motion. Most of the videos look similar in terms of background, but this turns out to help learn movement over time. Since the scene stays the same, the model is forced to pay attention only to how objects move.
In my tests, models trained on this dataset became very good at spotting small differences in how objects are handled. If your task depends on understanding fine actions like sliding, pushing, or rotating objects, Something-Something V2 trains the model to notice details that many other datasets miss.
Best for: depth estimation and 3D vision work
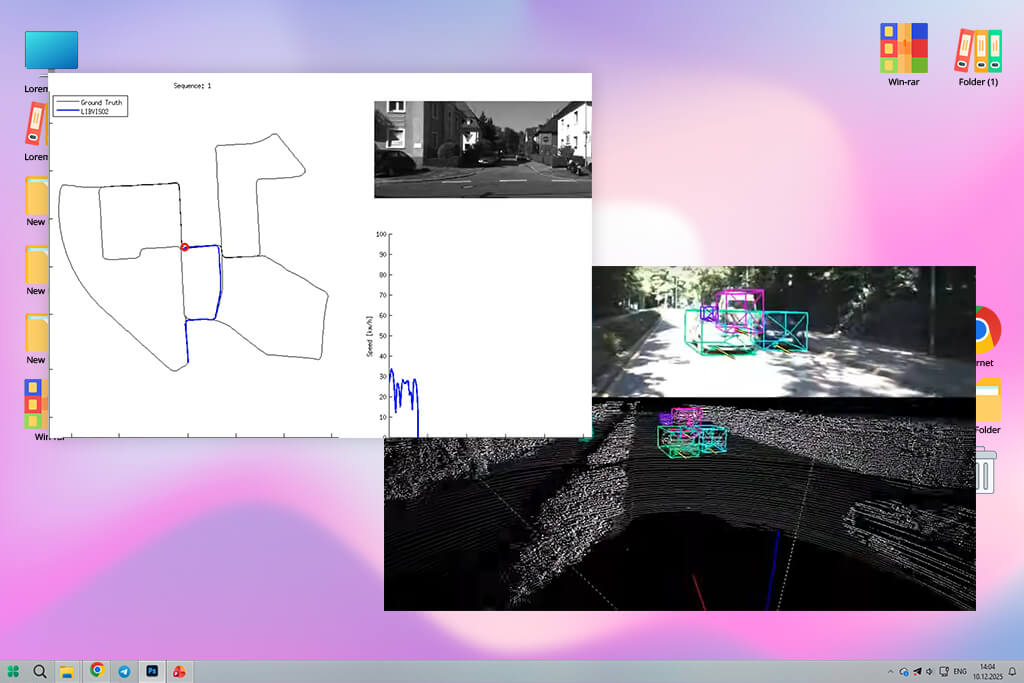
KITTI is known for its accuracy, but it covers only a limited set of driving situations. This is not a problem for tasks like depth estimation or 3D scene understanding. In fact, the controlled setup makes it easier to test and improve specific parts of a model.
Models trained on KITTI learn depth and distance well because the dataset combines LiDAR data with stereo cameras. When comparing 3D reconstruction or motion stability with tools like Adobe Firefly video model, KITTI’s clean structure makes results easier to judge.
For robotics, augmented reality navigation, or self-driving systems that rely on spatial understanding, KITTI remains an essential video dataset for machine learning despite its smaller size.
“I always pair KITTI with a synthetic depth dataset because it helps models generalize better in 3D tasks.”
A video dataset is a group of video clips that are used to teach AI systems how to understand movement, actions, objects, and how events change over time. Strong datasets include clear descriptions, steady camera views, and visuals that show meaningful actions instead of random motion.
The first step is to match the dataset to what your model needs to learn. For example, Kinetics works well for action recognition, COCO-VID for object tracking, DAVIS for video segmentation, and BDD100K is made for driving. After that, look at video quality, annotation style, and how many different environments and scenes are included.
Unedited videos often contain long breaks, shaky camera movement, or background activity that has nothing to do with the main action. Removing these parts helps the model train more smoothly and keeps its attention on what actually matters.
If your model needs temporal reasoning, training on video clips is the better choice. If the task focuses on single images, such as segmentation, using extracted frames can be faster and more effective.
The size depends on the task. Models that recognize actions usually need thousands of video clips to handle different situations. Segmentation models, on the other hand, can perform well with fewer videos if the annotations are clean and detailed, like in the DAVIS dataset.
These extra data types help models understand distance, shape structure, and how objects relate to each other in space, which is important for robotics, augmented reality, and self-driving vehicles.
Yes, using multiple video datasets for ML together often helps models work better on new data. Before training, you need to align things like frame rate, video resolution, and label formats so the data fits together properly.
To discover which video datasets actually help AI models improve, my colleagues from FixThePhoto and I tested each dataset in real training setups. We did not rely only on research papers or descriptions.
We followed our testing process to check each dataset for both technical quality and practical use. A good dataset must work not only in experiments but also in real projects. We looked at several key points:
Dataset design. How balanced the classes were, how long the clips lasted, whether the video resolution stayed consistent, and how accurate the labels were.
Training results. How fast models learned, how often they overfit, and how steady validation scores remained.
Task fit. How well each dataset supported tasks like action recognition, object tracking, video segmentation, and understanding motion over time.
Preparation effort. Whether videos needed to be trimmed, re-encoded, or relabeled before training could begin.
Use in real projects. My team members tested how well video datasets for machine learning worked in creative tasks such as gesture-based editing, object separation, and driving scene analysis.
Annotation reliability. Checking timestamps, bounding boxes, and segmentation masks for mistakes or missing data.
Overall usefulness. Whether the dataset helped models learn clear and useful patterns without adding extra noise.
In this guide, we kept only the machine learning video datasets that showed stable training behavior, strong understanding of motion, and dependable performance in real-world use.