If you are looking for a way to crawl information from various websites, I recommend using the best web crawler tools to cope with this task. They will make it easier to find duplicate content and broken links as well as solve major SEO issues. Using one of these programs, you can improve the quality of your website, increase its ranking and make it visible for search engines.
While compiling the list, I was paying attention to scalability and limitations, the quality of customer support and data. On this list, you will find both paid and free (open source) web crawling tools. To avoid performing data cleaning by yourself, I recommend choosing tools with a relevant built-in option.
Verdict: Netpeak Spider crawls websites to find any SEO optimization issues. By using this website crawler software, you can check more than 100 key SEO parameters, find more than 80 crucial internal optimization mistakes and discover duplicate content. The program offers Google Analytics and Search Console integration.
Netpeak Spider lets you find out whether your website is well-structured. It allows you to collect any data from web pages: prices, reviews, SEO texts, unique tags and article publication dates. Thus, you can create a high-level table with filtering or sorting options. Besides, this software analyzes source code and HTTP headers, supports an internal PageRank calculation, has a validator and Sitemap generator.
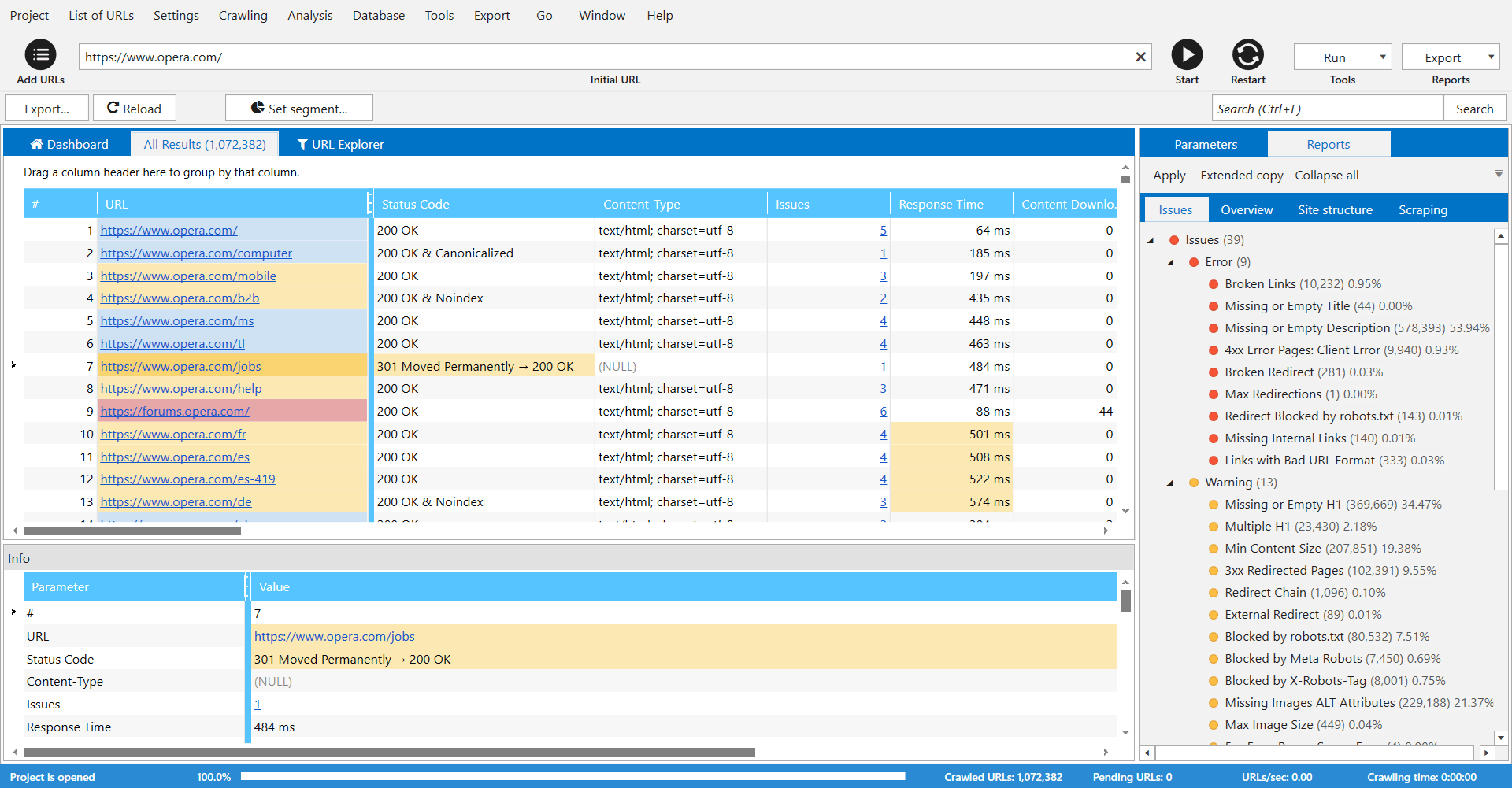
Verdict: Screaming Frog is the best online website crawler if your goal is technical and local SEO analysis. The program is available in paid and free versions, although the latter allows you to crawl only up to 500 URLs. Using Screaming Frog, you can easily check page titles and metadata as well as quickly identify broken links and server errors. The program integrates with various analytics services.
This SEO software will also help you create XML Sitemaps and identify duplicate content. When the crawling process is completed, you get a report for each page. It will send you info about the title, metadata, word count, H1 content, H2 content and the status code returned. In the headers tab, you can find the number of titles and their character length for each URL.
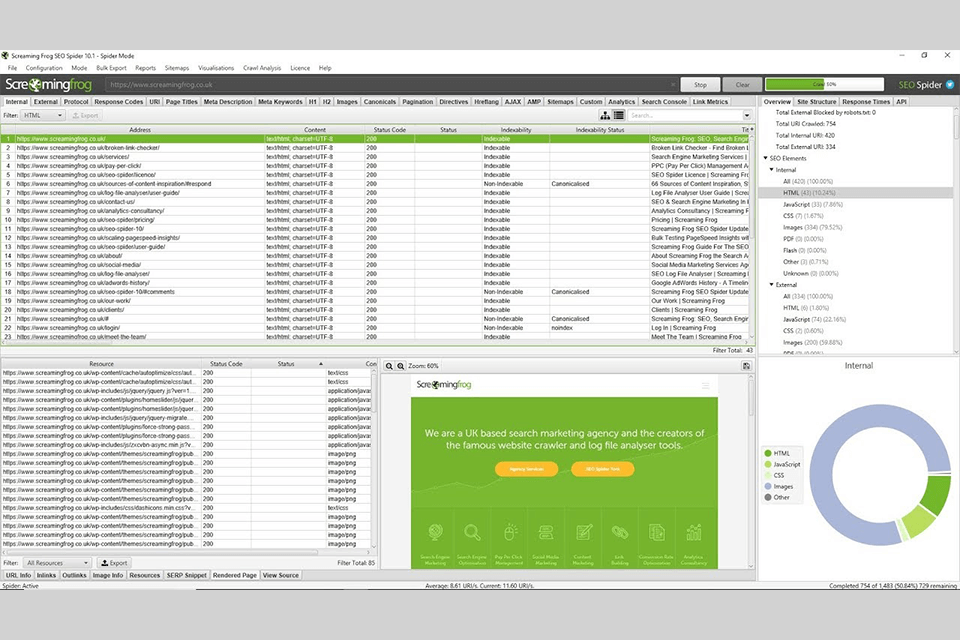
Verdict: HTTrack is an open source web crawler that lets you download a website from the Internet to your PC. The program can mirror one and several websites at a time if they have shared links. The “Set parameters” section will help you set the number of simultaneous connections for downloading pages.
With this tool, users can access photo content, files, HTML code from all directories. Besides, the program allows you to update the current mirror website and resume interrupted downloads. To build the structure of the website, you do not need to use third-party free mind mapping software. Thanks to proxy support, HTTrack delivers high-speed performance. Moreover, it follows JavaScript links.
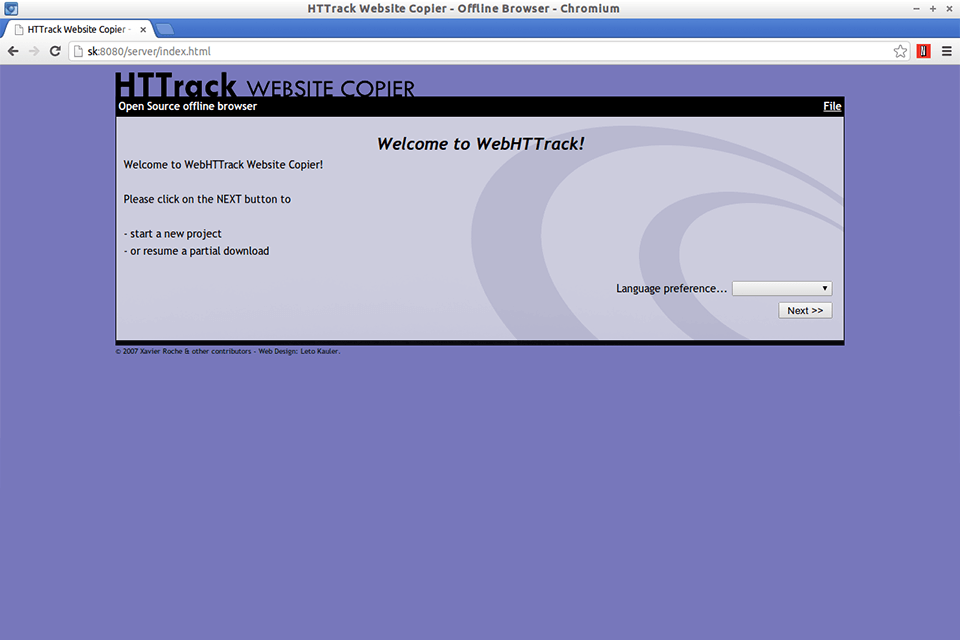
Verdict: WebHarvy is a web scraper that automatically collects any content from websites and also allows you to save this content in different formats. The service supports proxies and comes with an integrated scheduler. Similarly to a VPN for home, WebHarvy allows you to crawl anonymously and avoid being blocked by servers.
Users can get content from more than one page, keywords and categories. Besides, the service supports various export formats, like XML, CSV, JSON or TSV. Alternatively, you can export the scraped data to an SQL database. A nice bonus is the ability to run JavaScript code in the browser.
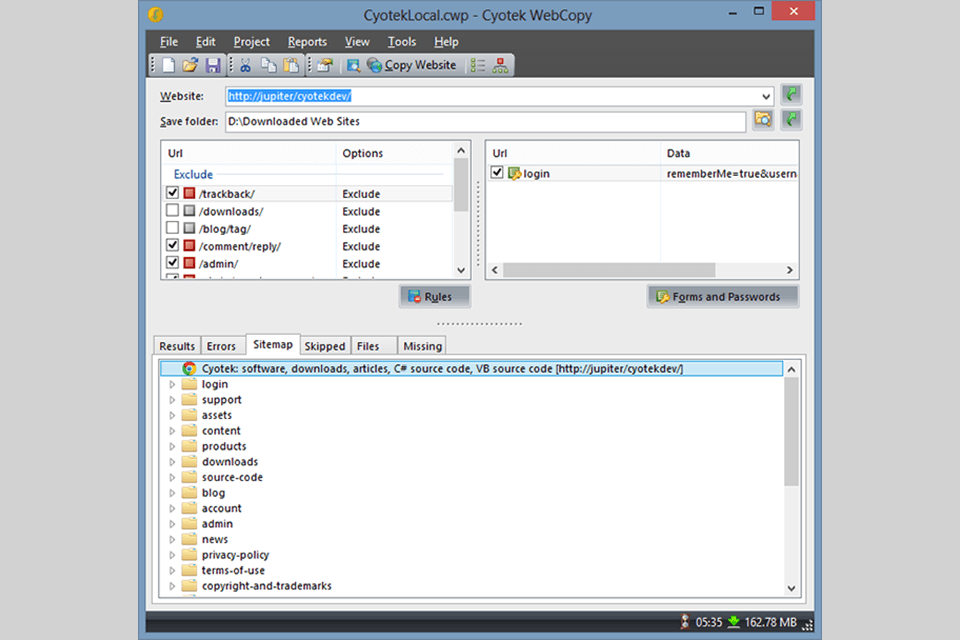
Verdict: Cyotek WebCopy allows you to quickly scan websites and download their content. It remaps links to stylesheets, images and other pages according to the local path. Users can select parts of a website to copy. Thus, you can create a copy of a static website for offline viewing or download any content.
If you would like to view websites offline, you can copy them to your hard drive using Cyotek WebCopy. Besides, all the settings can be customized. Users can change domain aliases, user agent strings, default documents, etc.
Verdict: ParseHub is a visual parser with a friendly interface and cloud integration. The service allows you to collect data from websites that use AJAX, JavaScript, cookies, etc. Thanks to machine learning technology, it analyzes web documents and transforms them into data.
You can fill out forms, work with interactive maps, calendars. It supports infinite scrolling. Select the target location on the page, and ParseHub will extract the necessary data from there. ParseHub desktop software is compatible with Windows, Mac OS X and Linux. Alternatively, you can work in a web application integrated into your browser.
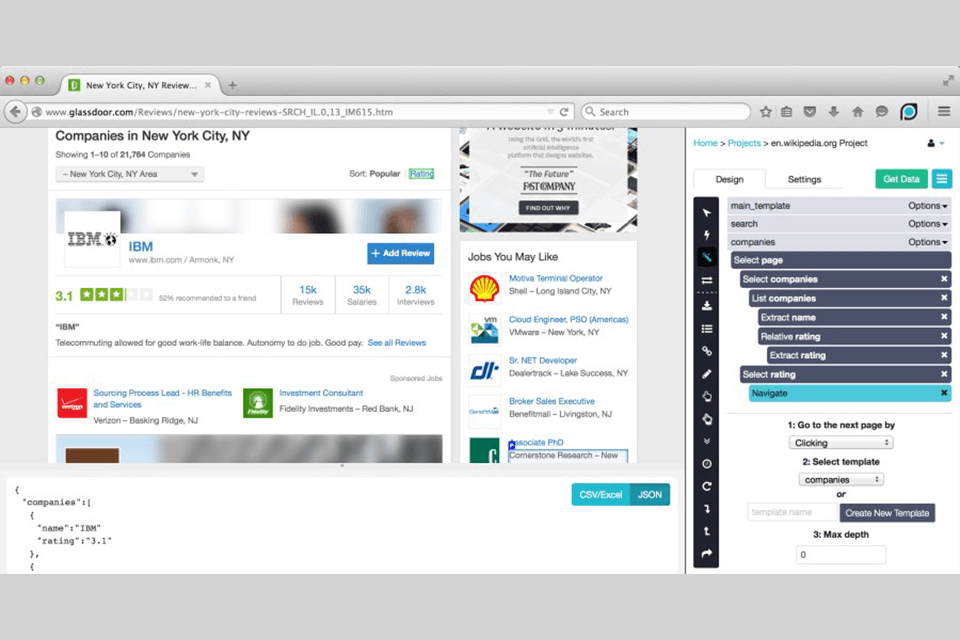
Verdict: Import IO can help you with web scraping if you need to analyze thousands of pages quickly without coding. Moreover, users can create 1000+ APIs that will meet their needs. Since web data can be quickly integrated into the application, the scanning process is quite simple. You can schedule crawling tasks.
Along with the web version, you can use free programs that are compatible with Windows, Mac OS X and Linux. They can be used for creating data extractors and crawlers that help download data and can be synchronized with your online account. Import. io works with various programming languages and analysis services.
Verdict: GrowMeOrganic is the top all-in-one prospecting tool I’ve tried for having unlimited data exports without ongoing credit purchases. Since it has both free and paid versions, I began with the 14-day free trial, which provided me with limited credits for all the features.
I used it to scrape unlimited LinkedIn contacts, find verified email addresses, and send targeted email campaigns with automated follow-ups. The system also integrates flawlessly with my CRM system and email provider, so it was extremely convenient to manage everything.
I also extracted local business data from Google My Business and searched a vast database of over 15 million businesses and 575 million professional contacts. The entire data I needed was available on the dashboard tab, where I could see all my prospecting activities and campaign outcomes in one window.

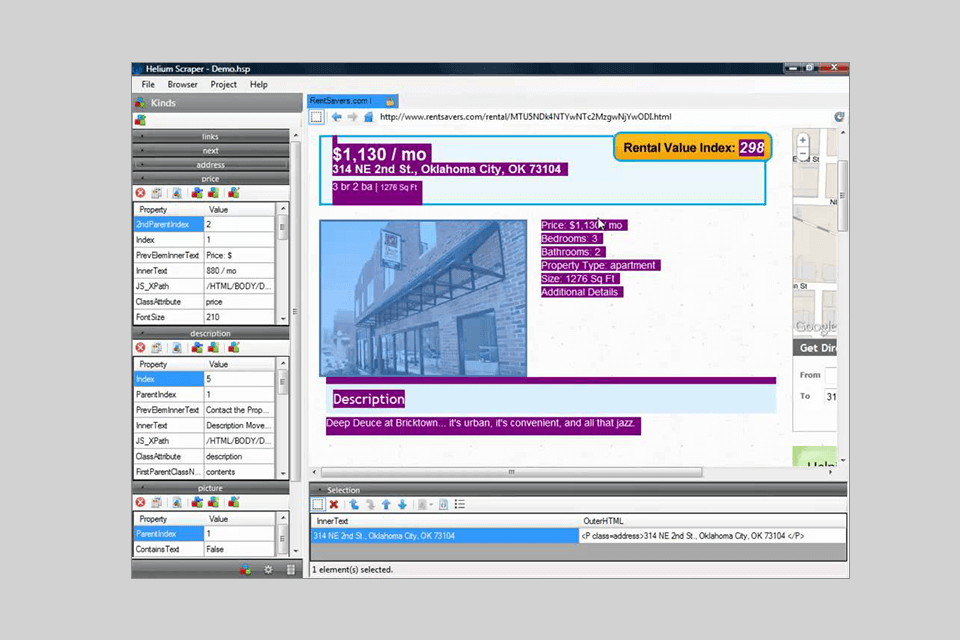
Verdict: Helium Scraper allows users to select the data they need to extract. By using the activated selection mode, you can find two similar samples, after which the tool will find copies of the elements automatically.
You can also use online templates that suit different crawling purposes. The program allows you to extract up to 100 records and supports various export formats. Helium Scraper quickly creates CSV or MDB Access databases where you can view the results, save them and write them to a spreadsheet.
Verdict: Thanks to the intuitive interface, Octoparse quickly saves text from websites. Using this website crawler software, you can get all the content and save it in EXCEL, TXT, HTML formats or as a private database. Thanks to the Scheduled Cloud Extraction option, the service can update websites to provide new information.
The integrated Regex function allows you to extract even complex websites with challenging data block layout. If you need to identify the location of web elements, I recommend using the XPath tool. Thanks to a proxy server, your IP address won’t be detected by websites.

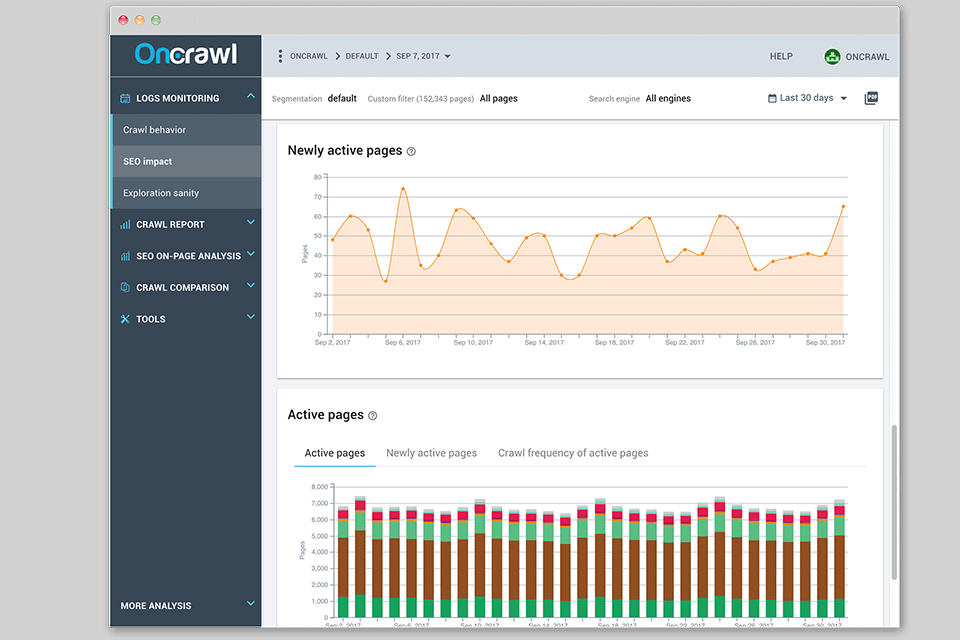
Verdict: OnCrawl can find out the reason why the indexation of your web pages was blocked. Using the service, you can import various data to crawl web pages. Besides, OnCrawl identifies duplicate content on the website. The program supports JavaScript code which allows it to crawl websites. Users can select two types of crawls.
When the crawling process is completed, users receive a full report where they can see the number of scanned pages, errors that can affect ranking and indexing, etc. Using the information on the relevant chart, you can find out more about the content, like headers, meta robots, status code, etc.
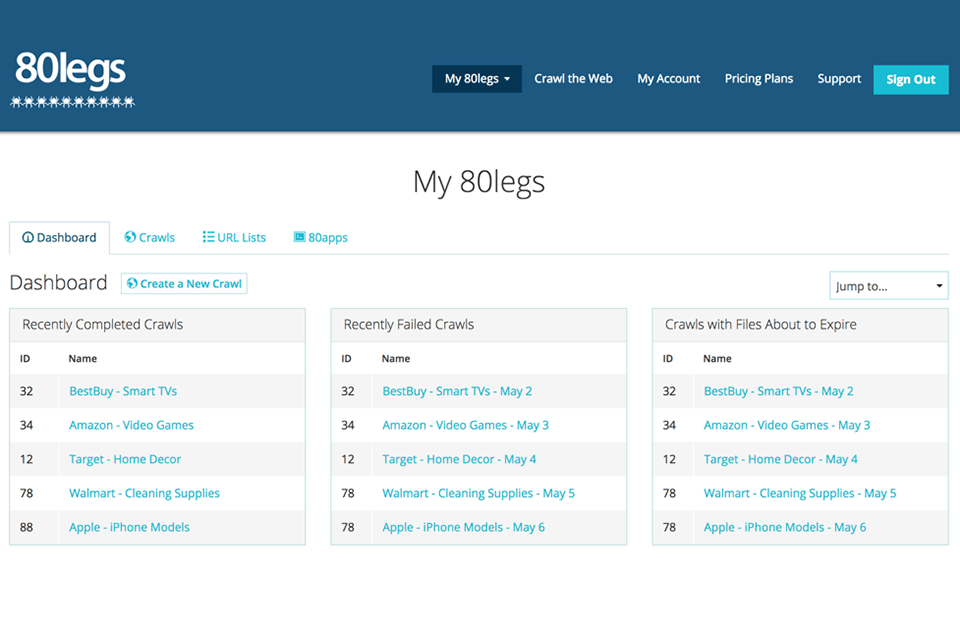
Verdict: 80legs offers several applications to choose from, with which you can quickly crawl a website by loading a list of links and indicating the crawling area. One of the applications included in 80legs is Keyword, which provides information on the number of requests for each link. You can also create your applications and unique codes.
80legs allows you not only to crawl large amounts of information but also to download this data in no time. The program provides free crawling of up to 10,000 URLs. Do not limit yourself to ready-made templates, because the service lets you create your unique ones. Based on on-site traffic, users can adjust the speed of the scanning process. You can save the results on a PC or an external drive.
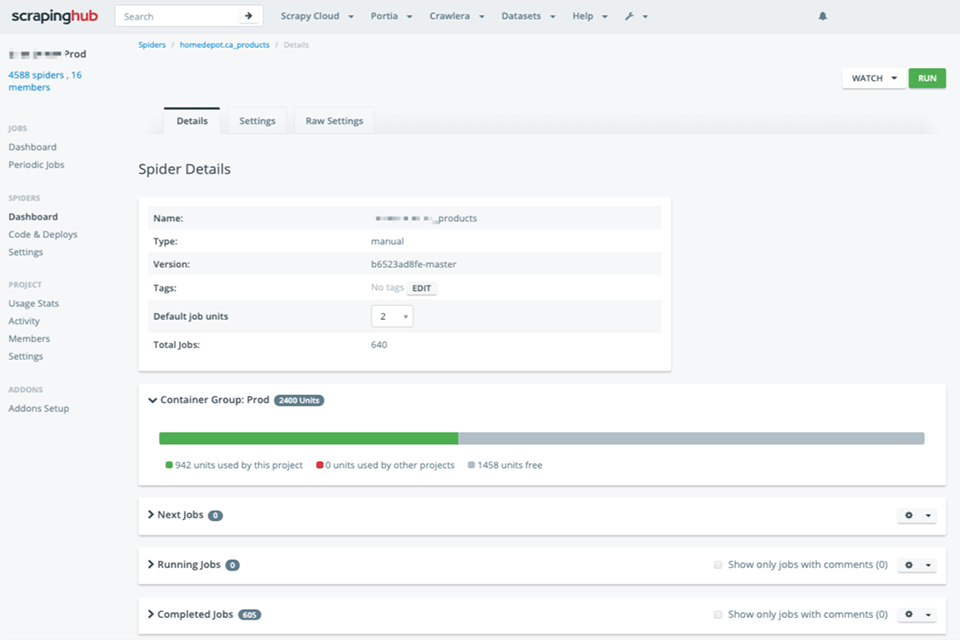
Verdict: Scrapinghub will help novice programmers or those lacking technical skills to quickly scrape a website. Thanks to the smart proxy rotator Crawlera, the service can bypass bot protection, which simplifies the process of crawling large websites. Using a simple HTTP API, you can perform the crawling process from multiple IP addresses and locations without issue.
The service does a great job of scaling your spiders without affecting the website architecture. Users can create and manage multiple spiders in no time. A nice bonus is helpful customer support.
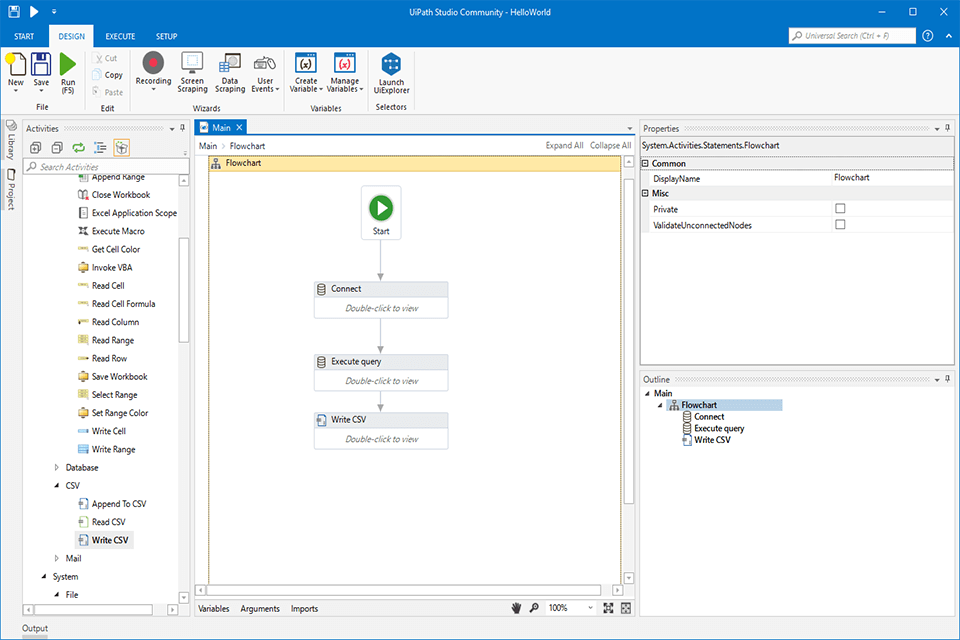
Verdict: UiPath is a free online web crawler that allows you to crawl data automatically from many third-party applications. You can get tabular data and use ready-made templates to extract data from websites. In addition to ready-made templates, UiPath offers a collection of customizable templates for different needs. You can use a desktop version or applications that are available through Citrix.
UiPath comes with integrated options for crawling. Besides, it has a screen scraping option designed for individual text elements and groups of texts. The screen scraper allows you to extract information in the form of tables. The service has launched the Studio Community platform, where it provides online training to all users and allows them to solve problems in groups.
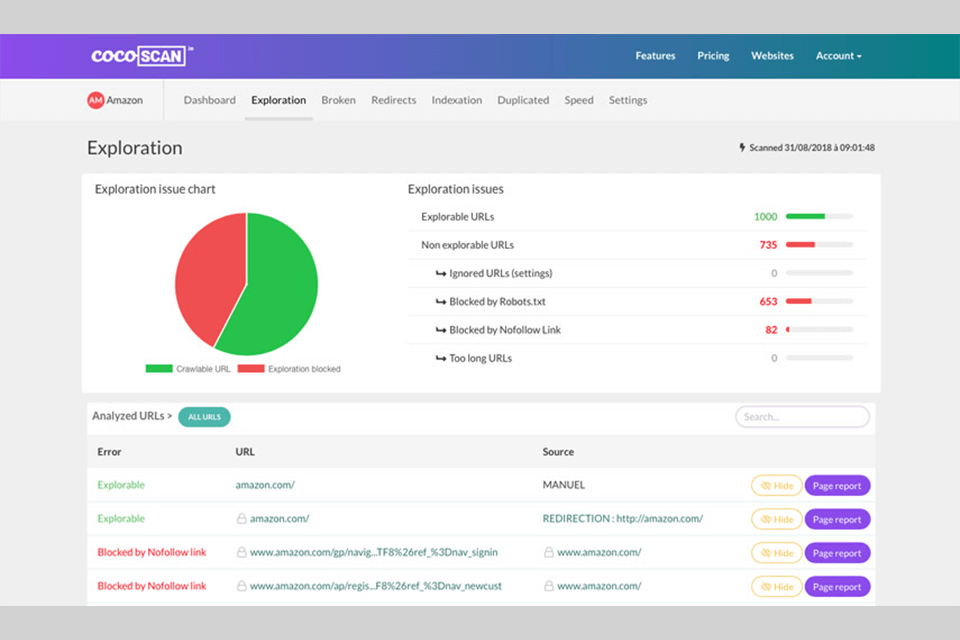
Verdict: Cocoscan provides information about duplicate content on websites and identifies top keywords. Through quick and easy website analysis, users can improve their rankings to make a website more search-engine friendly. Plus, Cocoscan delivers a real-time image of a responsive website.
After analyzing a website, you will receive a report with a list of problems that affect its ranking. A huge advantage is the ability to fix errors one by one and check individual pages where problems were solved. Cocoscan is designed for real-time crawling, allowing users to quickly complete tasks without waiting several days for results.
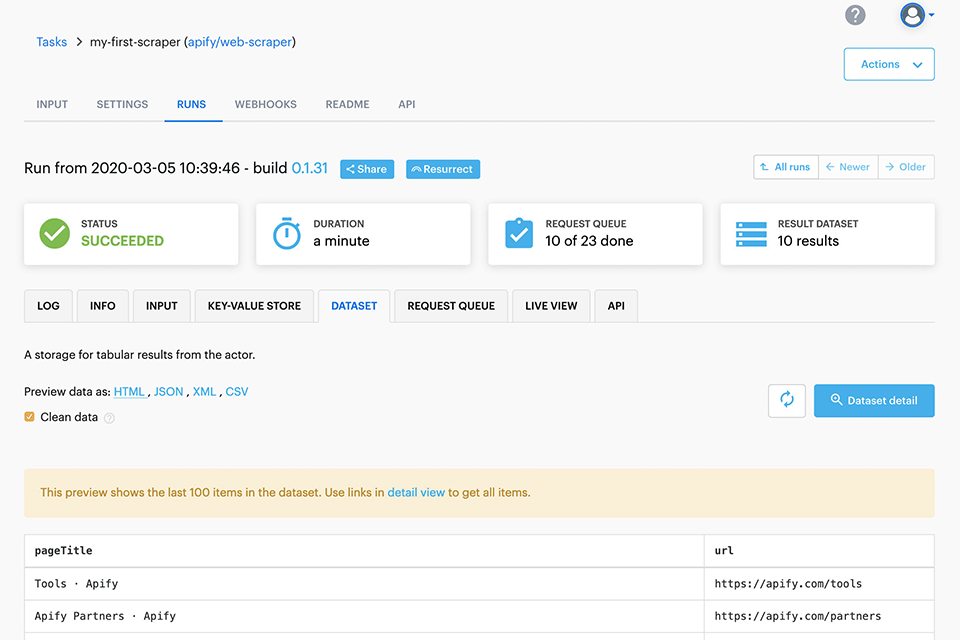
Verdict: Apify is known as one of the best web crawler tools for its ability to automate workflows and crawl entire groups of links. Using a scalable library, you can create data extraction and web automation tasks in Chrome and Puppeteer. The RequestQueue and AutoscaledPool options let you get started with multiple links and go to other pages. Besides, you can run scraping tasks at a high system capacity.
Apify supports URL queues for efficient crawling and scaling. To maintain your privacy, I recommend using Apify Cloud with multiple proxies.
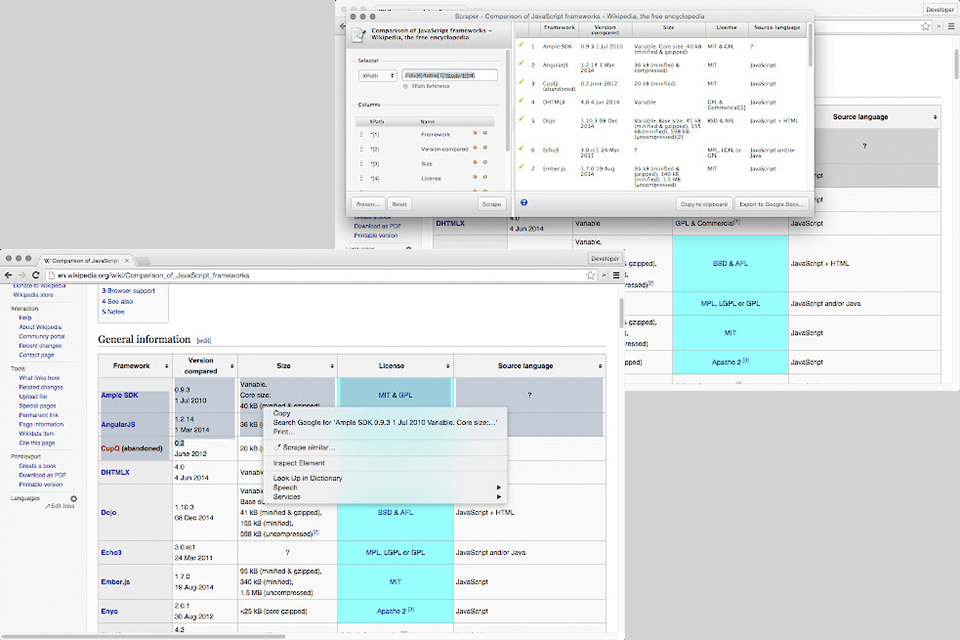
Verdict: Use Scraper if you are interested in online research and exporting data to Google Spreadsheets. It comes as a Chrome extension and easily copies information to the clipboard or stores it in spreadsheets using OAuth. Scraper generates smaller XPaths to identify website addresses for crawling.
Scraper is useful for detecting table header ending issues. It can collect rows with Tabular Data Stream. While it lacks advanced crawling options, it is easy to set up. If your goal is to optimize your website and increase its conversion, I recommend considering SEO services for photographers.