Вибір програмного забезпечення для генератора голосу на основі штучного інтелекту здається простим, доки вам не доведеться це зробити. Я зрозумів це на власному гіркому досвіді. Я знімав коротке відео та кілька пояснювальних роликів, і мені потрібен був реалістичний голос.
Записувати себе ніколи не було можливо. У мене не було пристойного мікрофона, і я терпіти не можу, коли відтворюють власний голос.
Найняти актора озвучування було поза моїм бюджетом. Тож я вирішив використати штучний інтелект. Я не очікував, як швидко все може піти шкереберть з неправильним інструментом. І повірте, існує багато неправильних інструментів.
Вибір найкращих генераторів голосу на основі штучного інтелекту зводився до одного – відповідності. Не до того, який інструмент мав найдовший список голосів, а до того, який з них насправді забезпечував те, що мені було потрібно: узгодженість, природний звук і реальний контроль над результатом.
Однак я не проходив цей процес сам. Мої колеги з FixThePhoto прийшли на допомогу. Разом з Кейт Дебелою, Вадимом Антипенком та Євою Вільямс ми протестували понад 40 ШІ-генераторів голосу щоб знайти найкращий.

Генератори голосу на основі штучного інтелекту – вражаючі інструменти, але після їх тестування можу сказати, що вони все ще мають деякі недоліки. Ось з чим ви зіткнетеся:

Штучний інтелект створює голоси за допомогою технології перетворення тексту в мовлення (TTS), яка працює на основі машинного навчання та нейронних мереж. Ось простий спосіб зрозуміти, як усе це працює:
Розбиття тексту на частини. Штучний інтелект починає з перегляду тексту та розбиття його на слова, речення та крихітні звукові одиниці, які називаються фонемами. Крім того, він звертає увагу на пунктуацію, щоб знати, коли потрібно зробити перерву або підвищити тон.
Навчені голосові моделі. Сучасні голосові інструменти зі штучним інтелектом працюють на моделях глибокого навчання (зазвичай нейронних мережах), які були навчені на незліченних годинах реального людського мовлення. Завдяки цьому навчанню вони з'ясовують, як люди вимовляють слова, змінюють тон, наголошують на певних складах та передають емоції у своєму голосі.
Створення звуку. Далі система бере весь оброблений текст і перетворює його на аудіо, створюючи звукові хвилі, які максимально відповідають справжньому людському мовленню. Більш просунуті моделі можуть точно налаштовувати тон, швидкість, висоту звуку та акцент, надаючи голосу природного відчуття, а не плоского та роботоподібного.
Налаштування стилю та настрою. Багато нейронних генераторів голосу на базі штучного інтелекту дозволяють вибирати з різних голосів, акцентів або стилів мовлення. Деякі моделі можуть навіть додавати емоції до міксу або налаштовувати голос відповідно до різних сценаріїв, таких як атмосфера оповіді або природна розмова.
Експорт аудіо. Після завершення готова промова зберігається як аудіофайл (MP3 або WAV). Пізніше ви можете вставляти її у відео, подкасти, ігри чи програми.
Голоси, створені штучним інтелектом, створюються шляхом навчання комп’ютерів, щоб вони розуміли, як люди розмовляють, а потім копіювали цю мову простим та повторюваним способом. Людям не потрібно сідати та записувати кожен рядок.
Коли я вперше сів за роботу з відеомоделю Adobe Firefly, я не мав настрою експериментувати. Мені потрібно було щось, на що я міг би реально покластися для комерційної роботи. Тож я написав чистий пояснювальний скрипт для вебсайту бренду та отримав нейтральний та професійний результат.
Потім я просунув це далі, написавши довший навчальний матеріал. Багато абзаців розповіді – це те, де багато онлайн-генераторів голосу зі штучним інтелектом починають руйнуватися, борючись зі зміною тону та темпу. Firefly не здригнувся. Він залишався стабільним протягом усього твору, а навколо більш щільних, технічних частин він навіть навмисно сповільнювався.
Звук не був схожий на читання зі сторінки штучним інтелектом, а радше на когось, хто робив це вже сто разів раніше.
«Я використовував сценарій-підручник, і цей інструмент мене не розчарував. Темп був ідеальним, а технічні слова вимовлялися правильно. Я думаю, що він надійний для брендованого контенту».

Я запропонував Firefly короткий промо-сценарій з деякими емоційними відтінками. Він не перебільшив. Я почув спокійну, приземлену впевненість – саме те, що мені було потрібно для представлення бренду. Мені особливо сподобалася послідовність. Я прослухав кілька дублів, і голос щоразу залишався рівним. Це дуже важливо, коли ви створюєте контент у великих масштабах і вам потрібно, щоб усе звучало цілісним.
Моя чесна думка полягає в тому, що Firefly справді готовий до роботи. Він не намагається бути крикливим чи розширювати творчі межі. Він вихваляється чіткістю, залишається послідовним та надає професійного вигляду всьому, до чого торкається. Це один з найкращих генераторів тексту в мовлення на базі штучного інтелекту для брендованої або корпоративної роботи.
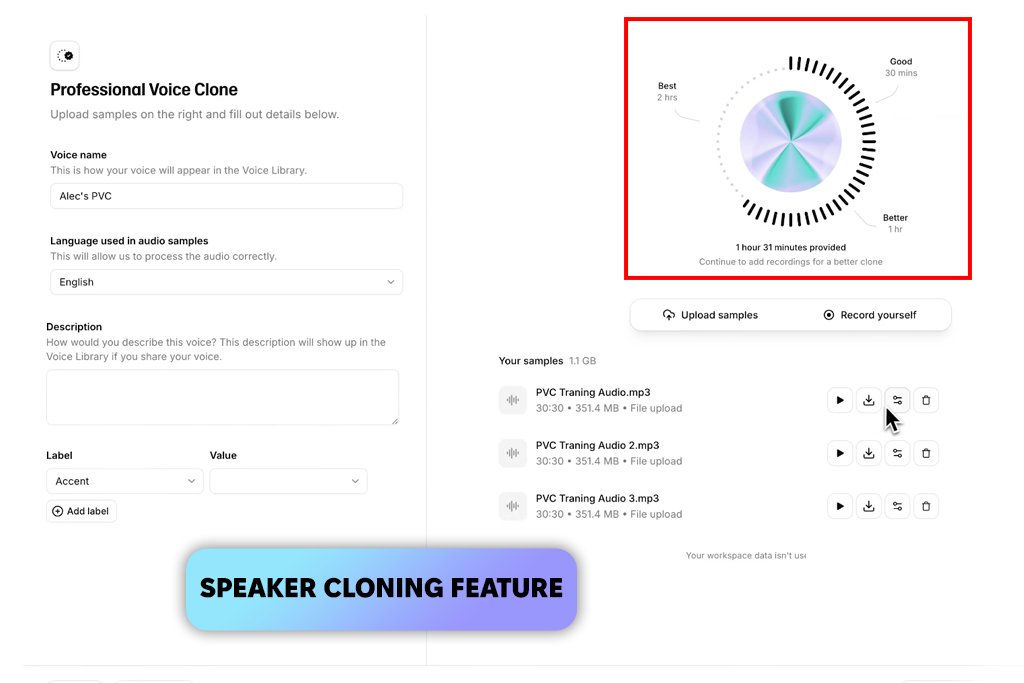
Я перепробував багато голосових інструментів. Більшість із них звучать як текст, що зчитується машиною. ElevenLabs все було інакше. Я вставив простий наративний сценарій, очікуючи звичайного роботизованого виводу. Натомість я отримав природні паузи, справжні емоційні зрушення та інтонацію, яка мала сенс. Перший інструмент за довгий час, який змусив мене переграти аудіо, просто щоб ще раз перевірити.
Потім я натиснув на це – переписав сценарій з напругою та хвилюванням. Він вловив кожну частинку цієї енергії. Потрібні слова були підкреслені, не звучачи перебільшено чи нав'язливо. Більшість генераторів закадрового голосу зі штучним інтелектом обробляють ваш текст. Цей щиро реагує на нього, що трапляється рідко.
«Я спробував сценарій розповіді, і кінцевий звук був належним чином емоційним. Він навіть імітував хвилювання та напругу. Рекомендую його для подкастів та лонг-ридів».

Далі я використав п'ятихвилинний сценарій. Голос залишався виразним, без затримок. Було кілька незначних проблем з вимовою, але нічого серйозного. Загалом, ElevenLabs винагороджує хороший текст. Чим більше зусиль ви вкладаєте у свій сценарій, тим кращий результат. Це вимагає трохи більше зусиль, ніж базові генератори голосу зі штучним інтелектом, але реалізм, який ви отримуєте в результаті, знаходиться на іншому рівні.
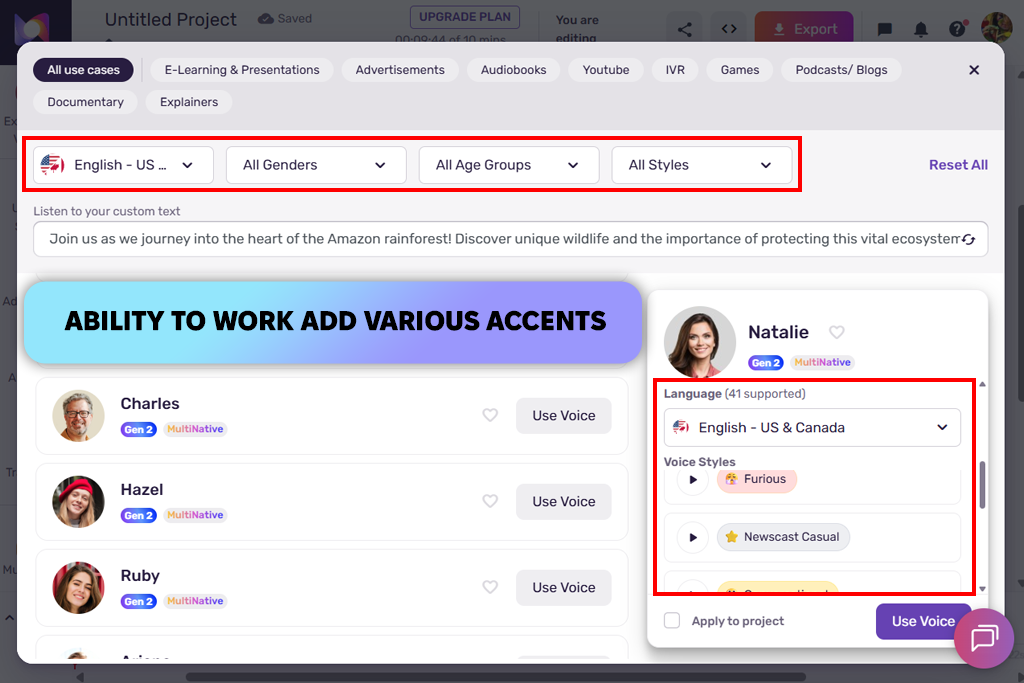
Murf AI перевершує багато аналогів з однієї конкретної причини. Він звучить професійно одразу після box . Інтерфейс чистий та інтуїтивно зрозумілий. Я вставив демонстраційний сценарій продукту, і результат майже миттєво став чітким, структурованим та відшліфованим. Це щиро нагадало мені добре зроблені корпоративні пояснювальні відео. Для навчального контенту ясність – це понад усе.
Далі я підправив висоту тону, швидкість і спробував отримати щось тепліше та більш розмовне. Це трохи допомогло, але Murf природно схиляється до формальності. Короткі речення звучали чудово, але довші абзаци здавалися дещо емоційно безжальними. Я думаю, що Murf не намагається звучати по-людськи. Він намагається звучати надійно. Це те, що потрібно для навчальних посібників, презентацій та професійних демонстрацій.
«Я використав його для демонстрації продукту та отримав чіткий та структурований звук. Короткі речення звучать природно, тоді як довшим абзацам може бракувати емоцій».

Коли я запускав тривалий навчальний модуль за допомогою цього ШІ-інструменту для аудіо, голос залишався надзвичайно стабільним від початку до кінця. Я не чув жодних випадкових стрибків тону чи незручних пауз. Все природно перетікало між реченнями. Якщо ви створюєте відео для адаптації або внутрішній корпоративний контент, це один з найкращих професійних генераторів голосу на основі штучного інтелекту.
Я також витратив деякий час на вивчення голосової бібліотеки та багатомовної підтримки. Вибір помірний. Нічого не перевантажує, але достатньо, щоб працювати. Деякі голоси звучать справді людськими, інші ж трохи роботизовані, тому варто перевірити, перш ніж робити вибір. Я також спробував різні акценти. Чіткість залишалася стабільною в більшості з них, хоча ледь помітні емоції були майже відсутні.
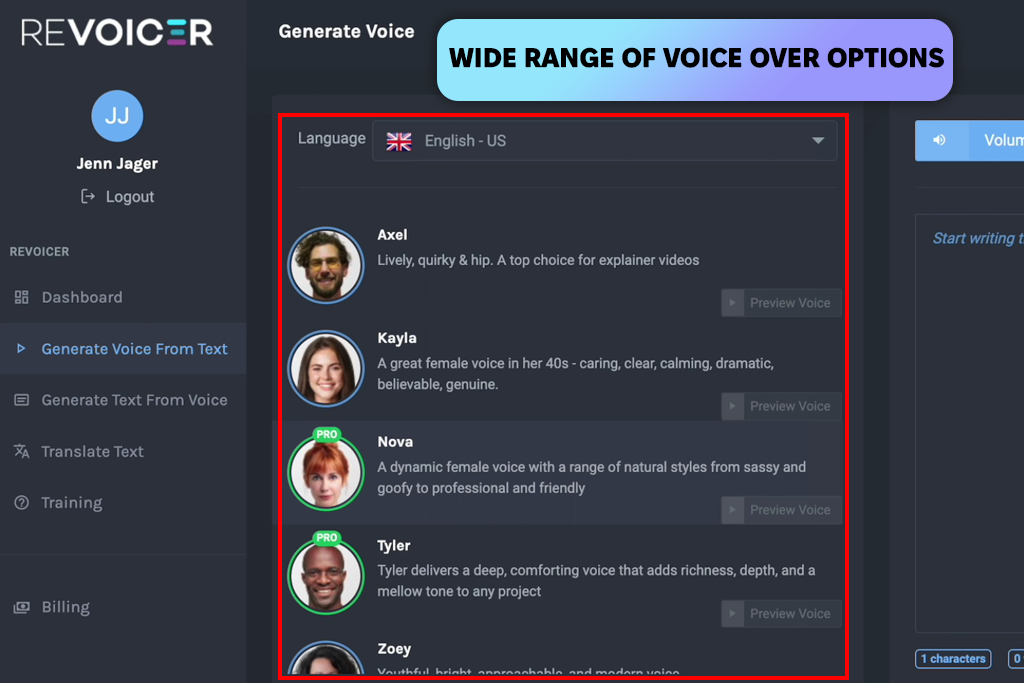
Я не очікував багато чого, коли вперше відкрив Revoicer , але він мене щиро здивував. Голос мав природну силу. Ключові фрази звучали з великою вагомістю, а енергія була правильною. Це було саме те, що мені було потрібно для короткої реклами. Кілька рядків трохи перебільшили драматизм, але нічого такого, що б вирішило проблему.
Потім я став амбітним і випробував це програмне забезпечення для озвучування на довших дикторських записах. Ось тут мені довелося сповільнитися. Енергія почала переміщатися між абзацами. Деякі речення звучали ненавмисно голосно, інші — трохи пласко. А паузи часом були незручними, ніби хтось забув дихати в потрібний момент.
«Я протестував це за допомогою короткого промо-сценарію. Голос, який я отримав, був гучним та енергійним без жодних налаштувань. Довший контент потребує налаштування, але ви можете покластися на нього для швидкої реклами».

Я також експериментував зі стилями оповіді та налаштуваннями тону. Змінюючи висоту тону, швидкість та акцент, я міг зробити голос більш розслабленим для легшого контенту. Він досить добре сприймав невеликі корективи, але відчуття високої енергії ніколи повністю не зникає. Я випробував його на всіляких сценаріях, і він найкраще справляється з короткими та різкими кліпами. Довші, спокійніші оповіді вимагали додаткового налаштування.
Я також протестував його для комерційного використання. Голоси сміливі та запам'ятовуються, що може допомогти бренду запам'ятатися людям. Проте, я б двічі подумав, перш ніж використовувати його для м'яких розповідей історій або довгих відео. Загалом, це один з найкращих генераторів мовлення на основі штучного інтелекту для реклами, соціальних мереж та оголошень, де гучність та енергійність насправді працюють на вашу користь.
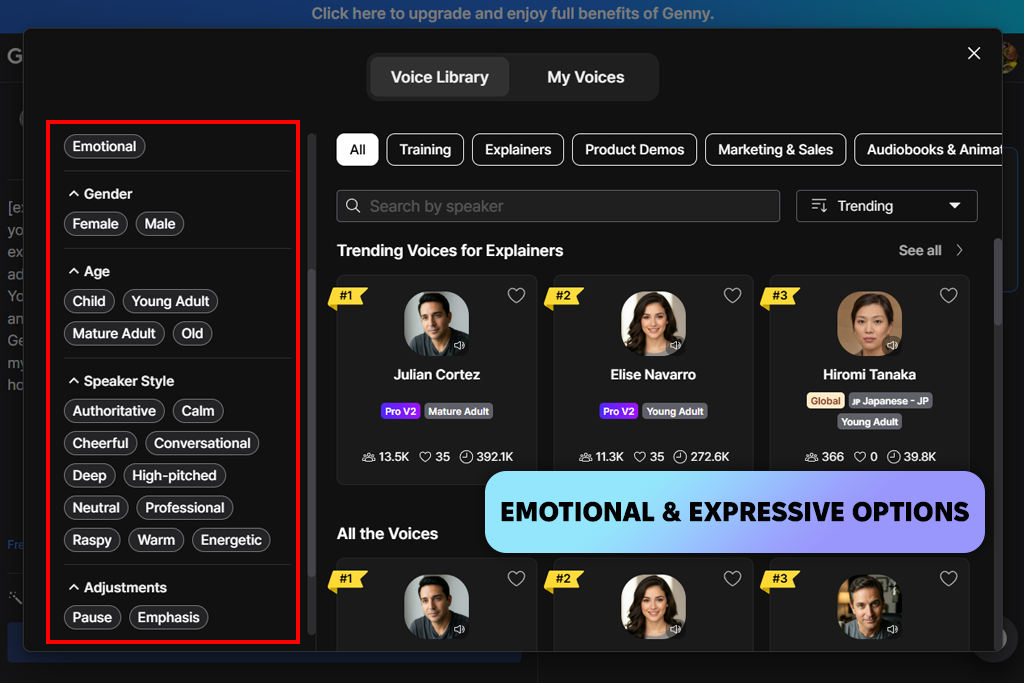
Коли я вперше запустив LOVO, я був здивований тим, наскільки все виглядало чисто та просто. Одних лише голосових опцій було достатньо, щоб зацікавити мене, тому я створив кілька коротких сценаріїв для соціальних мереж, щоб побачити, як це впорається з невимушеним діалогом. Перший вибраний мною голос здавався теплим і природним, ніби хтось справді розмовляє з вами.
Налаштувати швидкість і тон голосу було просто. Потім я перейшов до довшого пояснювального сценарію. Голос залишався чітким протягом усього тексту, але поруч зі справжнім оповідачем він здавався трохи емоційно плоским. Тим не менш, він звучав відшліфовано та легко сприймався. Випробовуючи різні голоси, я зрозумів, що вибір правильного може вплинути на те, наскільки захопливим буде ваш контент.
«Я використовував цей інструмент для створення голосів для відео в соціальних мережах. Він працював ідеально, особливо з короткими кліпами. Довші пояснювальні сценарії звучали дещо банально».

Я також протестував цей ШІ-генератор відео для брендового проєкту. Я обрав професійний тон, і він добре себе показав. Голос залишався чітким і відшліфованим – достатньо формальним для ділового середовища, але не напруженим. Я вніс кілька невеликих змін до швидкості та акцентів. Я точно можу уявити, як повернуся до цього генератора голосу зі штучним інтелектом для відео під час створення брендованого контенту для соціальних мереж.
Далі я проаналізував функцію кількох мов. LOVO пропонує широкий вибір акцентів та мов, хоча деякі звучали помітно плавніше за інші. Для тих, хто створює контент для глобальної аудиторії, така гнучкість є великим плюсом. Загалом, користуватися ним було легко, а експорт файлів був швидким і безпроблемним.
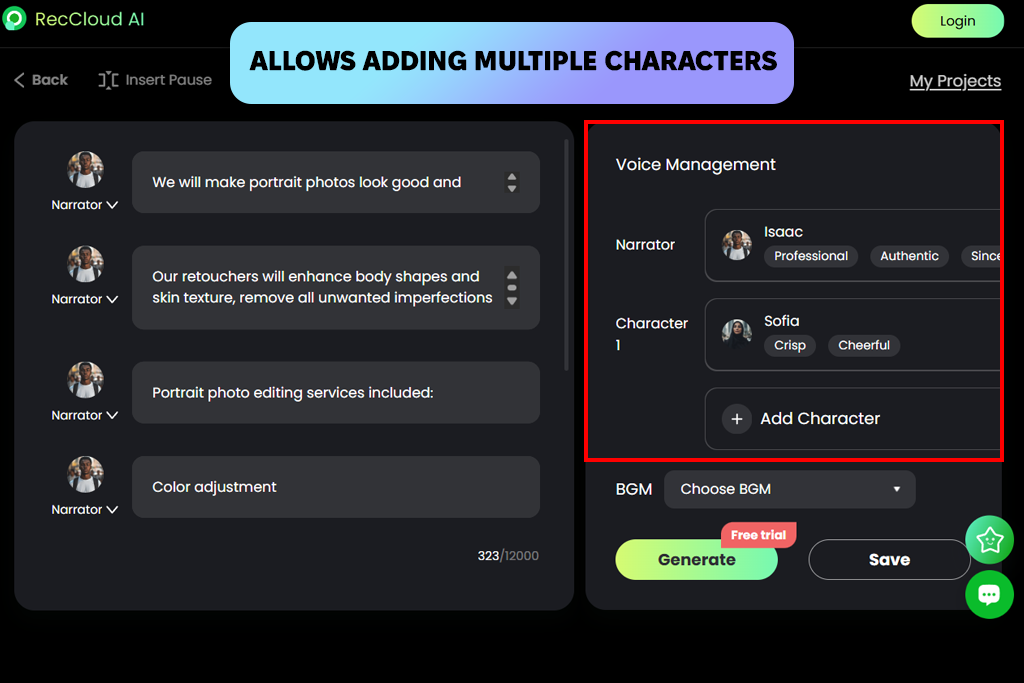
Коли я вперше спробував RecCloud , він виділявся серед інших генераторів голосу зі штучним інтелектом для творців контенту, але не найкращим чином. Результат був зручним, але мене одразу вразив роботоподібний звук. Я вставив короткий інструкційний сценарій, і результат швидко з'явився.
Щоб оцінити його можливості, я завантажив довший контент із кількох абзаців. Темп витримувався досить добре, але ритм був надто передбачуваним з часом. Йому бракувало людської плавності. Підправлення пунктуації трохи допомогло, але голос все одно звучав досить механічно.
«Я завантажив короткий навчальний сценарій і отримав результат майже миттєво. Голос був зрозумілим, але далеко не природним».

Я також протестував його з кількома мовами, і результати були неоднозначними. Англійська звучала найкраще, тоді як інші мови вийшли трохи більш роботоподібними. Для швидкого та простого озвучування він чудово справляється з завданням. Але він не такий універсальний, як деякі інші інструменти з мого списку.
Найбільшим недоліком є те, що він не обробляє генерацію мелодій, тому, якщо вам потрібна музика разом із закадровим голосом, вам доведеться використовувати окремий генератор музики зі штучним інтелектом, щоб заповнити цю прогалину.
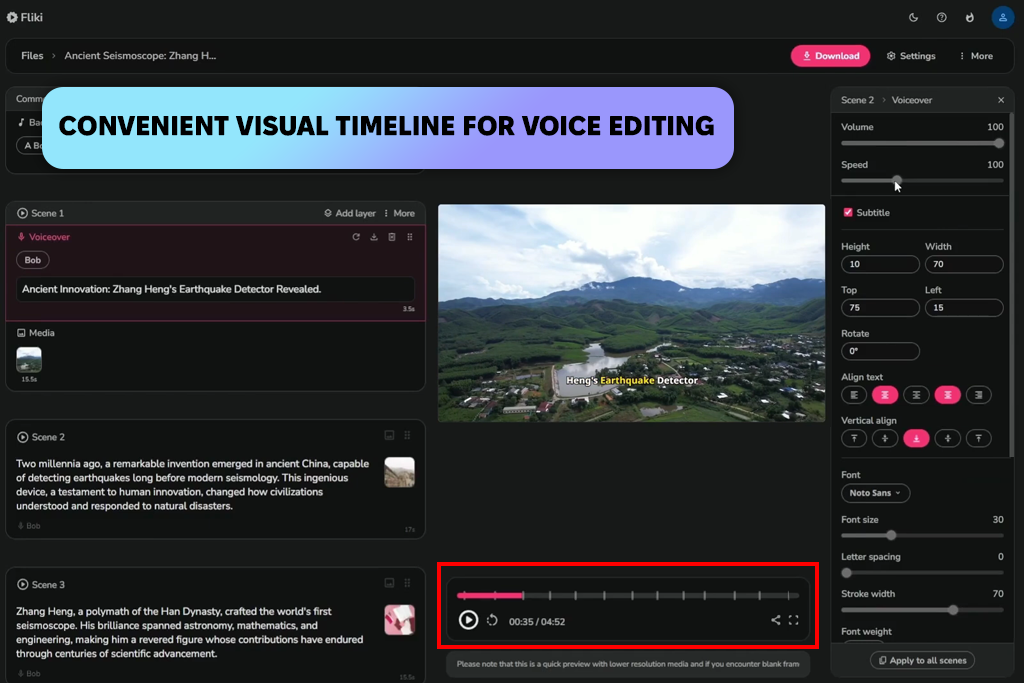
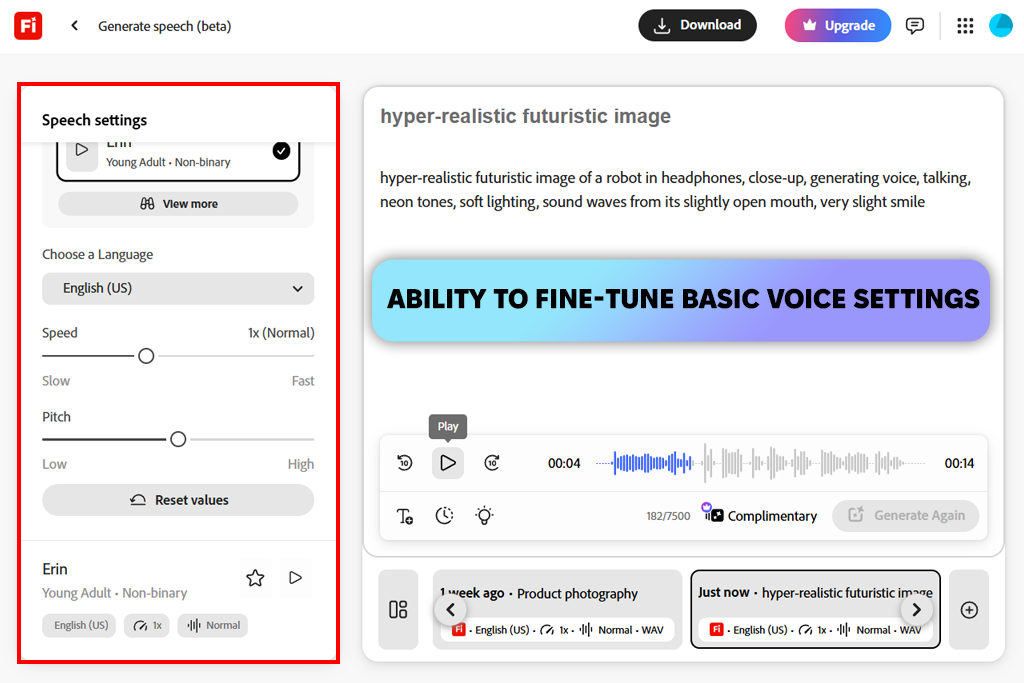
Я натрапив на Fliki , працюючи над коротким відео, яке потребувало візуальних елементів. Поєднувати текст з відео було легше порівняно з іншими інструментами, які я використовував раніше. Закадровий голос природно поєднувався з субтитрами та тим, що відбувалося на екрані, тому мені не довелося витрачати час на самостійне налаштування таймінгу. Звук був стабільним і чистим, навіть якщо він не був надто виразним.
Загалом, Fliki є одним із найкращих реалістичних генераторів голосу зі штучним інтелектом для людей, які хочуть отримати швидкі результати.
«Я використовував цей інструмент для короткого відеопроекту. Голос правильно синхронізувався з візуальними ефектами, особливо коли речення були короткими. Я думаю, що цей інструмент чудово підходить для швидких відеопроектів».

Я також завантажив сценарій для оповіді. Він добре справлявся з короткими рядками, але довші абзаци виглядали трохи роботоподібно. Налаштування швидкості та висоти тону трохи вплинуло на результат, тоді як розрізання сценарію на короткі розділи було дуже корисним. Стало цілком зрозуміло, що Fliki більше підходить для швидкого, розбитого на частини контенту, ніж для довгої оповіді.
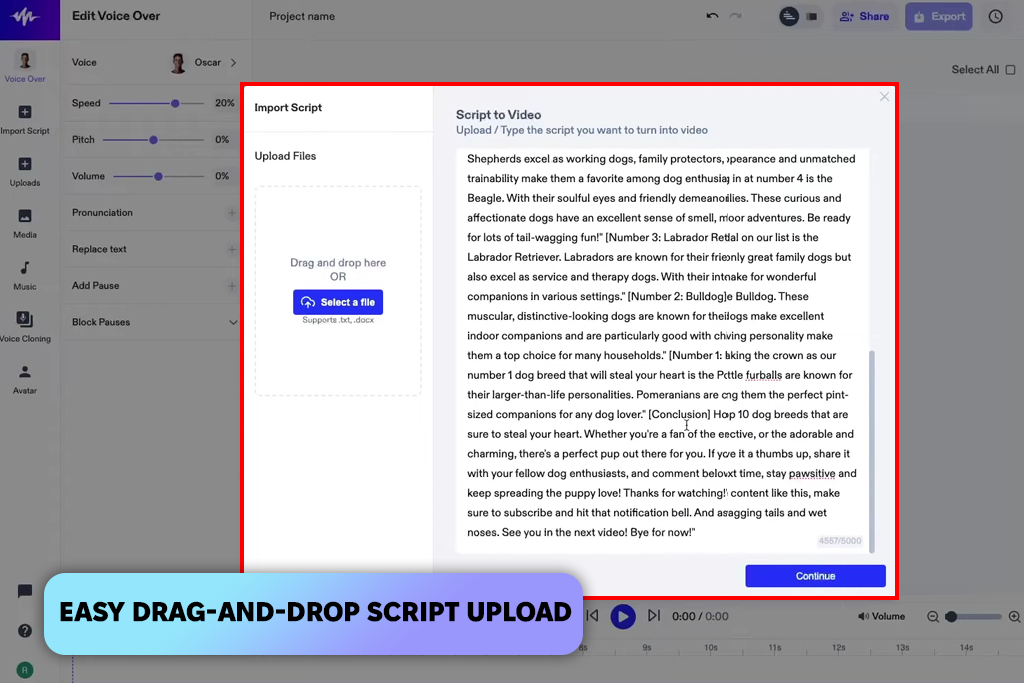
Під час тестування Speechify я використовував повсякденний розмовний текст, щоб побачити, наскільки добре він зможе встигати за темпом. Він спрацювали краще, ніж я очікував, природно підхоплюючи ключові слова, не перебільшуючи емоцій. Темп був ідеальним, завдяки чому було легко стежити за текстом і слухати його справді приємно. Здається, це надійний генератор штучного інтелекту, що звучить людським голосом, для пояснювальних відео або освітніх подкастів.
«Я завантажив статтю та отримав природний голос. Наголоси були правильно зроблені, тому слухати матеріал було комфортно. Результати були задовільними навіть із довгим контентом».

Далі я завантажував великі фрагменти контенту один за одним. Голос залишався плавним і послідовним протягом усього часу, без дивних змін тону чи проблем із темпом. Невеликі зміни пунктуації допомагали з паузами. Його було справді легко слухати. Однак налаштування мало деякі обмеження. Швидкість і голос працювали добре, але емоційна глибина та контроль акцентів були досить простими.
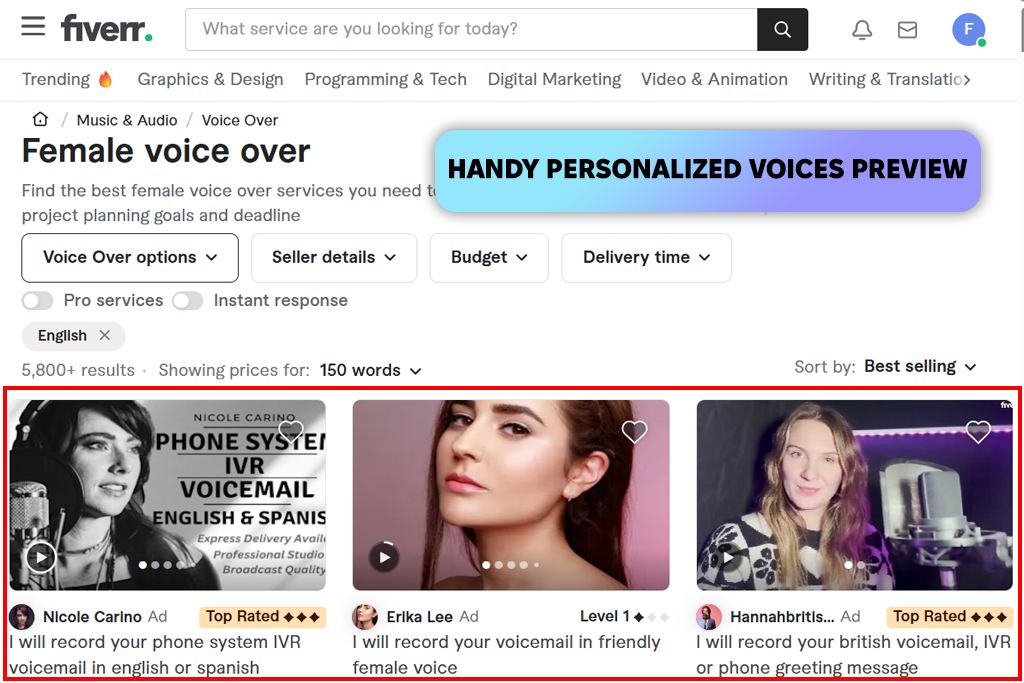
Було дуже цікаво спробувати Fiverr . Це цілий торговий майданчик, а не просто окрема технологія генерації голосу зі штучним інтелектом. Я переглянув пропозиції щодо голосу зі штучним інтелектом, і різниця в якості та стилі між продавцями була досить разючою. Я замовив короткий озвучуваний текст, щоб побачити, як організовано весь процес.
Чим чіткіше ви формулюєте свої інструкції, тим кращий результат. Правки вимагали певних зусиль, але зрештою я знайшов те, що відповідало моїм задумам. Fiverr вимагає більше практичних зусиль, ніж просто використання автоматизованого генеративний інструмент штучного інтелекту .
«Я придбав короткий запис голосового супроводу зі штучним інтелектом і мені сподобався результат. Якість залежить від постачальника, тому важливо давати чіткі інструкції. Деякі голоси чудові, а інші залишають бажати кращого».

Налаштування замовлення означає спілкування з продавцями безпосередньо. Немає жодних налаштувань чи елементів керування для самостійного налаштування. Це одночасно і добре, і погано. Ви отримуєте більше гнучкості, але це уповільнює процес. Ціни також сильно різняться, тому пошук різних варіантів допомагає. Це найкраще підходить для нішевих або вузькоспецифічних стилів спілкування.
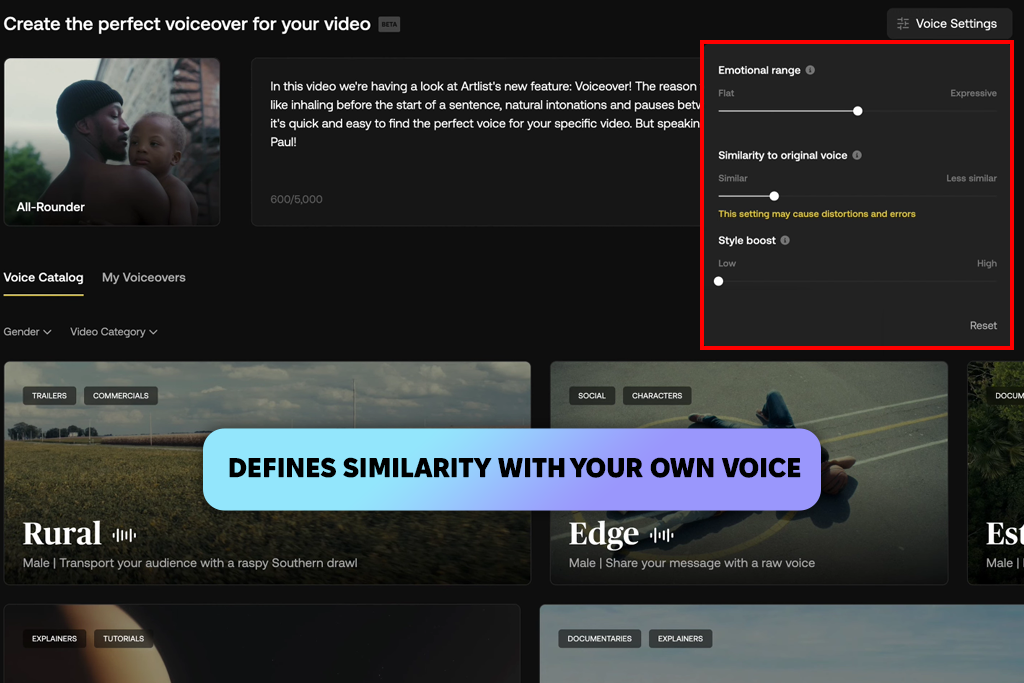
Я протестував штучний голос Artlist на реальному відеопроекті, і він справді вразив мене. Звук вийшов чистим і кінематографічним, одразу поєднуючись з фоновою музикою. Потім я запустив у нього фірмовий сценарій, щоб перевірити, наскільки добре він справляється з більш формальним тоном. Він залишався зібраним і професійним протягом усього відео. Емоційна глибина була мінімальною, але для корпоративних відео він ідеально влучив у ціль.
«Це дало чудові результати з моїм брендованим відео. Промова ідеально відповідала фоновій музиці та візуальним ефектам. Емоційний діапазон був обмеженим, але ледь помітним».

Стилі озвучування досить різноманітні. Деякі були холодними та нейтральними, тоді як інші виглядали оптимістичними для рекламного використання. Зручно перемикати стилі, щоб отримати різні варіанти звучання. Найкраще те, що якість була незмінно хорошою протягом кожного тесту, який я проводив.
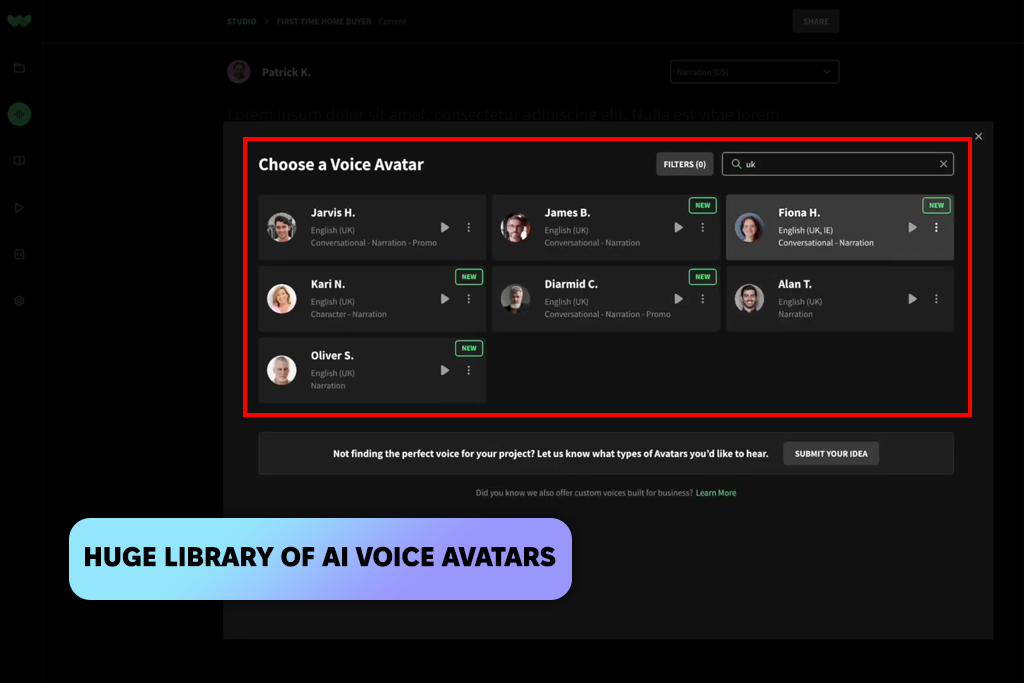
Я протестував WellSaid Labs із корпоративними сценаріями озвучування, і він мене швидко вразив. З самого першого рядка голос був впевненим і чистим, але не скутим. Він ідеально справлявся з технічними термінами. Зазвичай саме тут безкоштовні генератори голосу зі штучним інтелектом не справляються, але цей витримав добре. Він нагадав мені справжнього актора озвучування, який точно знає, що робить у професійному середовищі.
«Я створював впевнені та точні голоси для корпоративних сценаріїв. Вимова була чудовою, навіть під час роботи з технічними термінами. Я просто застосував кілька простих налаштувань для наголосу».

Я також витратив деякий час на перегляд варіантів голосу та акценту. Вибір був невеликий, але кожен голос з бібліотеки був чистим та професійним. Багатомовна вимова досить добре відповідала повсякденним термінам, хоча іноді незвичайне слово потребувало невеликого налаштування, щоб звучало правильно.
Однак, одна річ, яка мене дратувала, це відсутність вбудованої функції редагування. Тож, коли я тестував додаток, мені довелося знайти окреме безкоштовне програмне забезпечення для редагування аудіо щоб виправити деякі проблеми.
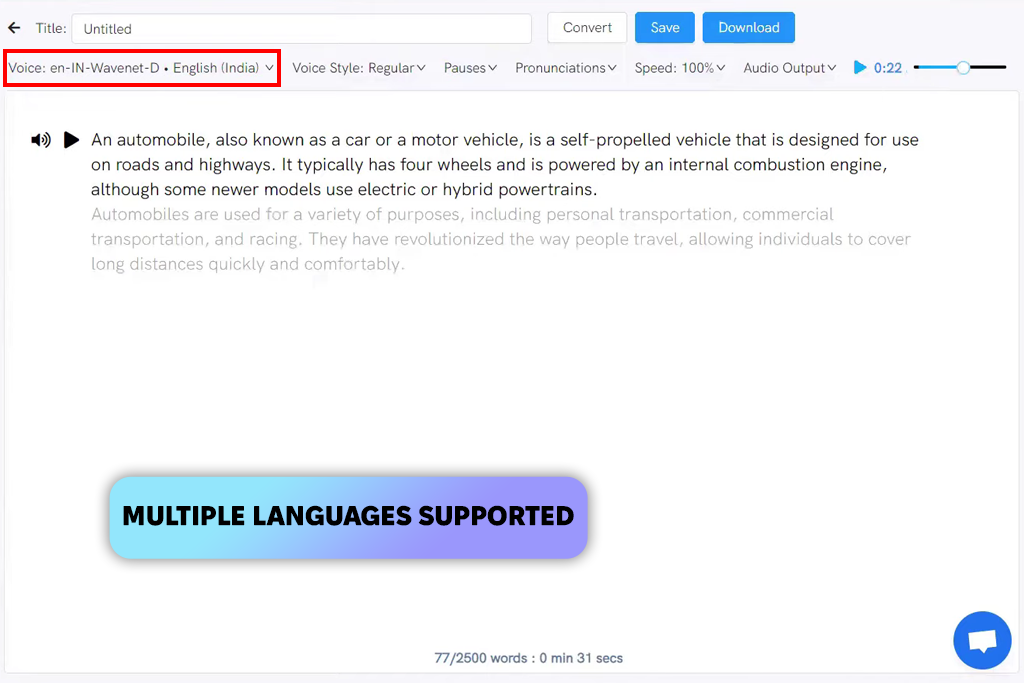
Щоб оцінити можливості Listnr, я використав сценарії в стилі подкастів. Голос був чистим і зрозумілим, без надто драматичних моментів. Швидкість, з якою він конвертував текст в аудіо, приємно мене здивувала. Для тих, кому потрібен простий і надійний дикторський супровід, це здається досить непоганим вибором.
«Я протестував цей інструмент зі сценарієм у стилі подкасту. Голос був чітким і послідовним, але без емоцій. Усі паузи були точними, і загалом ним легко користуватися».
Я програв кілька секцій поспіль, щоб перевірити, чи голос залишатиметься стабільним протягом усього твору. Ритм тримався досить добре, але чим довше він звучав, тим більше він починав здаватися трохи повторюваним. Кілька невеликих налаштувань тут і там допомогли згладити все. На мою думку, цей Listnr — чудовий генератор голосу на основі штучного інтелекту для створення простого, інформативного контенту.
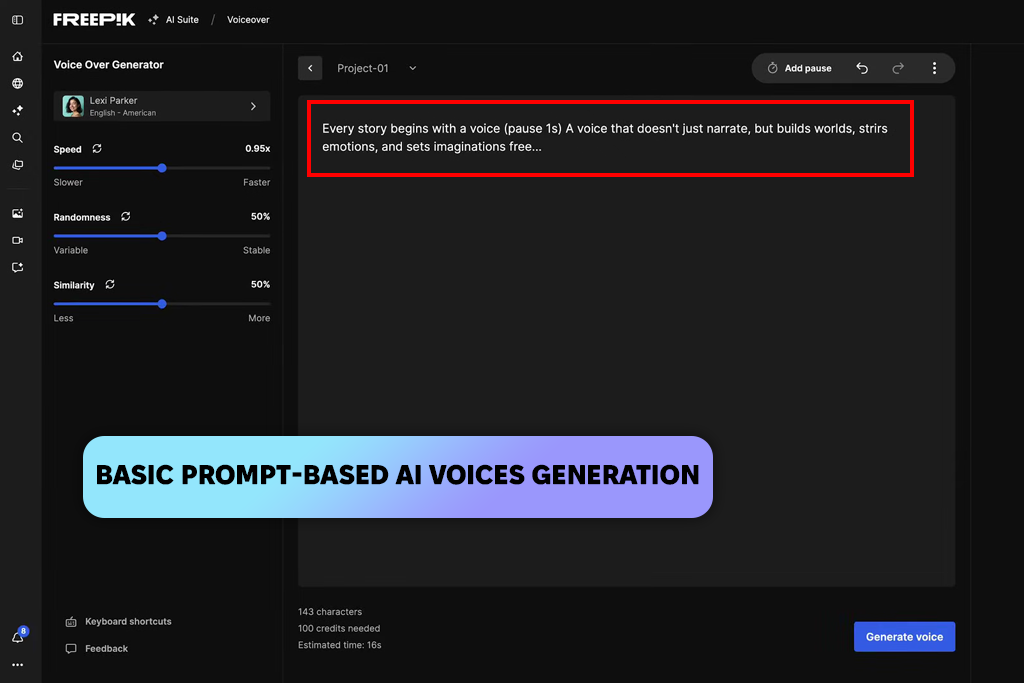
Щоб протестувати штучний голос Freepik , я використав свій дизайнерський проєкт. Короткі сценарії звучать пристойно та легко читаються, але довші мене розчарували. Це зручно, коли вам просто потрібно швидко озвучити візуальні ефекти. Я пробував різні голоси та акценти, але відмінності не дуже помітні. На мою думку, це непоганий інструмент для візуальних ефектів, але він відстає від спеціально створених генераторів штучного інтелекту, що звучать як людина.
«Я протестував його для швидких дизайнерських проектів, і він працював напрочуд добре. Короткі сценарії звучали чітко та чисто. Довший контент здавався роботоподібним. Чудово підходить як бонус до візуальних елементів або коротких кліпів».
Я також використовував його для озвучування кількох абзаців. Це працювало нормально, але довші сценарії чітко дали зрозуміти, що голос має проблеми з виразом та ритмом. Я застосував деякі ручні виправлення, але на довших ділянках він все одно звучав роботизовано. Загалом, штучний голос Freepik найкраще працює як швидке та зручне доповнення для простого озвучування, коли ви вже використовуєте його для візуальних ефектів, а не як основний інструмент озвучування.
Наша команда тестування складалася з трьох членів Команда FixThePhoto: Кейт Дебела, Вадим Антипенко та Єва Вільямс. Кейт перевірила чіткість і точність вимов. Вадим звернув увагу на швидкість і послідовність мовлення. Єва оцінила, наскільки добре голоси виражали емоції.
Щоб об’єктивно протестувати кожен генератор голосу на базі штучного інтелекту, ми використовували однакові скрипти в усіх інструментах. Це включало короткі дописи в соціальних мережах, навчальні посібники, рекламний контент і довші навчальні матеріали.
Кейт позначала будь-які роботизовані або неправильно вимовлені слова. Вадим перевіряв, чи темп залишався стабільним, особливо в довших частинах. Єва перевіряла емоційність подачі – чи голос звучав схвильовано, спокійно чи професійно, залежно від змісту. В одному тесті використовувалося оголошення бренду. В іншому – п’ятихвилинний технічний інструктаж.
Далі ми оцінили, наскільки реалістичним та практичним звучав кожен інструмент. LOVO добре працював для невимушених сценаріїв, але йому бракувало емоційної глибини в довгому контенті. Revoicer здавався сміливим та енергійним, що робило його чудовим для короткої реклами, хоча довші сценарії потребували додаткових налаштувань.
Murf AI найкраще показав себе для навчальних посібників та корпоративного контенту завдяки своєму чіткому, структурованому тону. ElevenLabs вразив нас природним звучанням розповіді та плавними емоційними переходами. Adobe Firefly був стабільним та надійним для брендових та освітніх матеріалів.
Ми також розглянули швидкість, налаштування та зручність використання. Кейт перевірила, як швидко кожен інструмент відтворює аудіо та наскільки просто налаштувати висоту тону, швидкість та акцент. Вадим перевірив параметри експорту, підтримку мов та інтеграцію відео. Єва оцінила кожен інструмент за виразністю та тим, наскільки «людським» він звучав.
Загалом, LOVO та Fliki підходили для короткого контенту в соціальних мережах, тоді як Murf AI , WellSaid Labs та ElevenLabs краще підходили для довших, професійних оповідей.
Наша команда перевірила кожен інструмент генерації голосу на основі штучного інтелекту в реальних ситуаціях, оцінюючи чіткість, емоційність, узгодженість та зручність використання. Об’єднавши висновки Каті, Вадима та Єви, ми створили чесний та всебічний огляд, який допоможе вам обрати правильний інструмент для вашого проєкту.



![9 найкращих ШІ-генераторів хедшотів [Вибір FixThePhoto {{%year}}]](/placeholder-450x300.svg)