
Hoogwaardige fotobewerking is de basis voor effectieve AI-training. FixThePhoto levert professioneel geretoucheerde, perfect gestructureerde datasets voor machine learning, die AI-modellen duidelijke, consistente visuele voorbeelden bieden om van te leren. Elke afbeelding wordt bewerkt door deskundige retoucheurs, wat nauwkeurigheid, realisme en een kwaliteitsstandaard garandeert.


Onze datasets omvatten portretten, lifestyle, productfoto's, vastgoed, commerciële afbeeldingen en meer. Deze diversiteit stelt ontwikkelaars in staat om precies het bewerkingsdomein te kiezen dat hun AI moet leren – met de kwaliteit en consistentie die alleen professionele retoucheurs kunnen bieden.
Toevoegen

Verwijderen
Vervangen
Het seizoen verandert.
Actie
tellen
Maak een schets
Achtergrond wijzigen
Cartoonstijl
Relatie
Vervang tekst
Object extraheren
AI-modellen presteren het best wanneer ze leren van schone, consistente en professioneel bewerkte afbeeldingen. Bewerkte datasets bieden een duidelijke visuele logica voor taken zoals fotoverbetering, achtergrondvervanging, huidretouchering, kleurcorrectie en productoptimalisatie voor e-commerce. Wanneer de trainingsdata verfijnd zijn, kan AI gemakkelijk patronen herkennen en resultaten van hoge kwaliteit reproduceren.
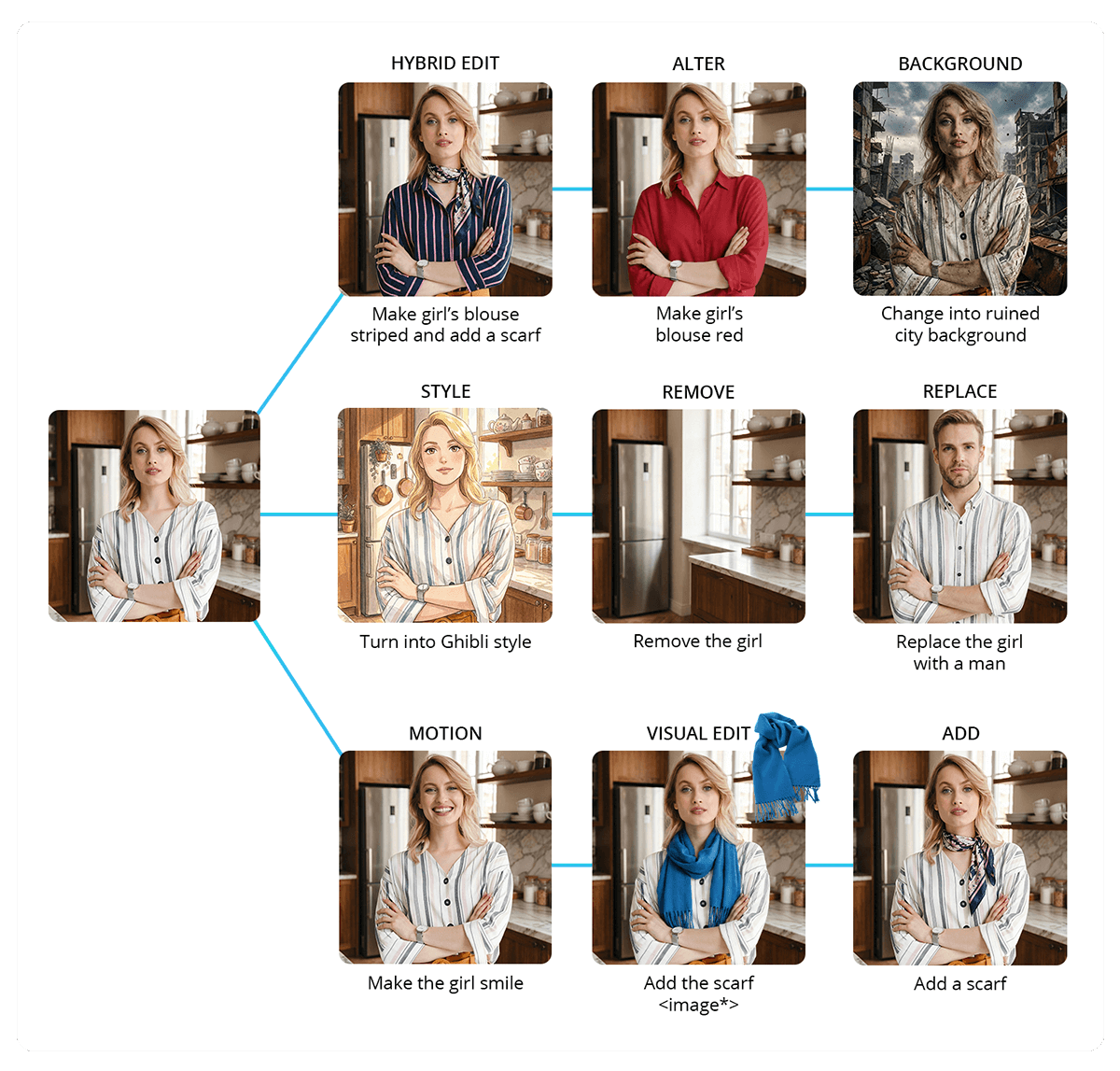
Datasets van lage kwaliteit of onbewerkte datasets voor AI-training introduceren problemen die de AI snel overneemt: zichtbare artefacten, te gladde of onnatuurlijke huid, onjuiste kleurbalans en inconsistente randen. Deze gebreken maken het model onbetrouwbaar en ongeschikt voor professioneel gebruik.

De professioneel bewerkte fotobewerkingsdatasets van FixThePhoto zijn ontworpen ter ondersteuning van een breed scala aan AI-toepassingen. Ze bieden de schone, consistente visuele data die modellen nodig hebben om realistische bewerkingstechnieken te leren en betrouwbare resultaten te leveren.

Deze datasets met AI-fotobewerkingssoftware zijn ideaal voor het trainen van AI-retoucheertools die portretten of productfoto's verbeteren, en voor het verbeteren van in-app fotofilters met consistente, professionele effecten. Ze helpen ontwikkelaars bij het bouwen van AI-tools voor het verwijderen van achtergronden met nauwkeurige maskering en strakke randen, en modellen voor fotoverbetering in e-commerce die zorgen voor accurate kleuren, schaduwen en productconsistentie.
FixThePhoto werkt samen met een divers scala aan klanten die afhankelijk zijn van professionele datasets voor fotobewerking om hun AI-systemen te trainen en te verbeteren. Onze samenwerkingspartners omvatten AI-ontwikkelaars en technologiebedrijven die tools ontwikkelen voor fotoverbetering, achtergrondverwijdering, huidretouchering en kleurcorrectie.
We werken ook samen met fotografen, merken en studio's die op zoek zijn naar aangepaste datasets die specifieke bewerkingsstijlen weerspiegelen en consistentie garanderen in grote beeldcollecties. E-commerceplatforms en productgerichte bedrijven gebruiken onze datasets om AI-modellen te trainen voor een accurate productpresentatie, consistente kleuren en schone achtergronden.
Ongeacht de branche of projectomvang levert FixThePhoto vakkundig bewerkte, hoogwaardige datasets voor fotobewerking, gebaseerd op deep learning, waarmee klanten AI-modellen efficiënt, betrouwbaar en op grote schaal kunnen trainen.
De AI-trainingsdatasets van FixThePhoto voor fotobewerking zijn zorgvuldig gestructureerd om duidelijke, consistente en hoogwaardige voorbeelden te bieden voor machine learning-modellen. Onze dataset bevat 386.000 hoogwaardige, zorgvuldig samengestelde bewerkingsparen, die zowel bewerkingen met één als met meerdere stappen ondersteunen.

Elke dataset bevat gepaarde voor-en-na-afbeeldingen, waarbij de originele foto naast de professioneel bewerkte versie wordt getoond. Dit formaat stelt AI in staat om de exacte transformaties te leren die door professionele retoucheurs worden toegepast, van kleurcorrectie en belichtingsaanpassing tot gedetailleerde huid- of productretouchering.
Datasets voor fotobewerkingstraining kunnen ook optionele maskers en segmentatiebestanden bevatten, die een nauwkeurige scheiding van onderwerp en achtergrond mogelijk maken voor AI-taken zoals compositing, achtergrondvervanging of objectherkenning. Elke afbeelding is gelabeld en georganiseerd op basis van bewerkingstype, categorie en stijl, waardoor eenvoudige integratie in trainingspipelines wordt gegarandeerd.
Met duizenden van afbeeldingen die consistent zijn bewerkt, biedt de dataset een rijke, betrouwbare basis voor AI-modellen om professionele fotobewerkingstechnieken te leren.
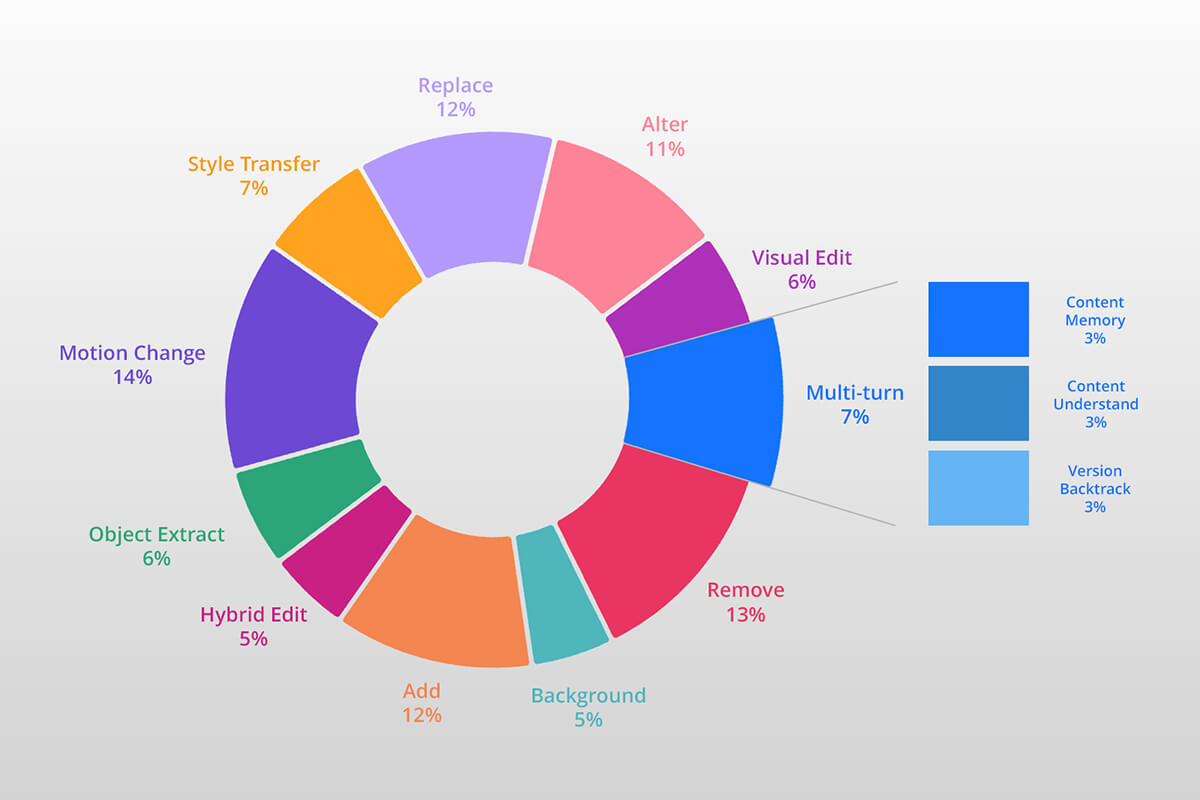
Onze AI-datasets voor fotobewerking omvatten een breed scala aan bewerkingstypen, waardoor AI-modellen diverse voorbeelden krijgen voor effectief leren. Deze omvatten bewegingsveranderingen, objectverwijdering, kleur- en belichtingsaanpassingen, en toevoegingen of verbeteringen. Andere bewerkingstypen zijn aanpassingen, bewerkingen met meerdere stappen, stijltransformatie, visuele bewerkingen, objectextractie, achtergrondaanpassingen en hybride bewerkingen.
De datapipeline van FixThePhoto zorgt ervoor dat de trainingsdatasets voor AI-fotobewerking nauwkeurig, consistent en geschikt zijn voor machine learning. Het proces begint met het genereren van prompts, waarbij duidelijke instructies en bewerkingsdoelen worden gedefinieerd om de creatie van elk beeldpaar te begeleiden. Dit zorgt ervoor dat elk voor-en-na-voorbeeld een specifieke transformatie of retoucheertaak weerspiegelt.
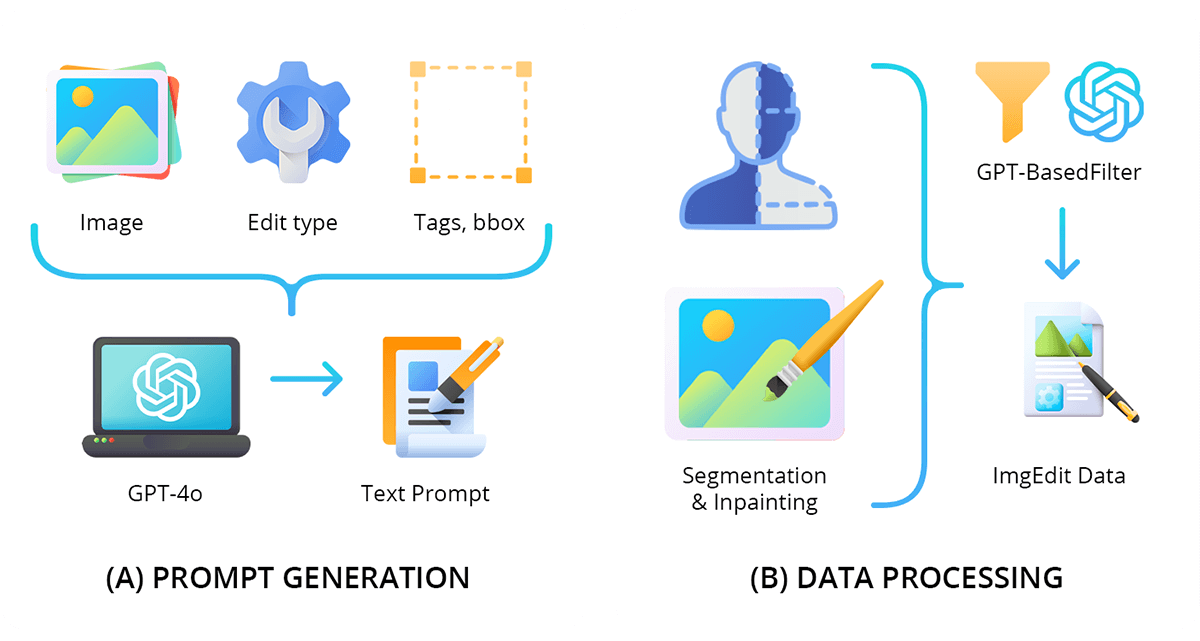
Volgende is dataverwerking, waarbij afbeeldingen zorgvuldig worden georganiseerd, gelabeld en voorbereid voor AI-integratie. Dit omvat opmaak, kwaliteitscontroles, het maken van optionele maskers en het toewijzen van metadata. Door deze gestructureerde pipeline te volgen, levert FixThePhoto schone, goed georganiseerde trainingsdatasets voor machine learning-fotobewerking, waardoor AI-training efficiënter, betrouwbaarder en effectiever wordt.


De kwaliteit van deze datasets voor AI-training is ongeëvenaard. Elke afbeelding wordt consequent geretoucheerd, waardoor de training van onze AI-huidretoucheringstool veel sneller en nauwkeuriger verliep.

De datasets van FixThePhoto voor machine learning bespaarden ons team maanden handmatig werk. De voor-na paren en schone maskers stelden onze AI voor achtergrondverwijdering in staat studiokwaliteit te bereiken.

We hebben verschillende fotobewerkingsdatasets geprobeerd, maar geen enkele was zo betrouwbaar en professioneel bewerkt als die van FixThePhoto. De consistentie over duizenden afbeeldingen is ongelooflijk.

De aangepaste datasets die ze leverden, pasten perfect bij de esthetiek van ons merk. Het was alsof we een heel team van professionele retoucheurs voor ons hadden werken.

Het gebruik van de fotobewerkingstrainingdataset van FixThePhoto verbeterde de mogelijkheden van onze AI voor productfotografie-verbetering aanzienlijk. De nauwkeurigheid van kleur- en randcorrectie is uitstekend.